







Machine learning is transforming maintenance by predicting issues before they happen, cutting costs, and improving asset reliability. Here’s what you need to know:
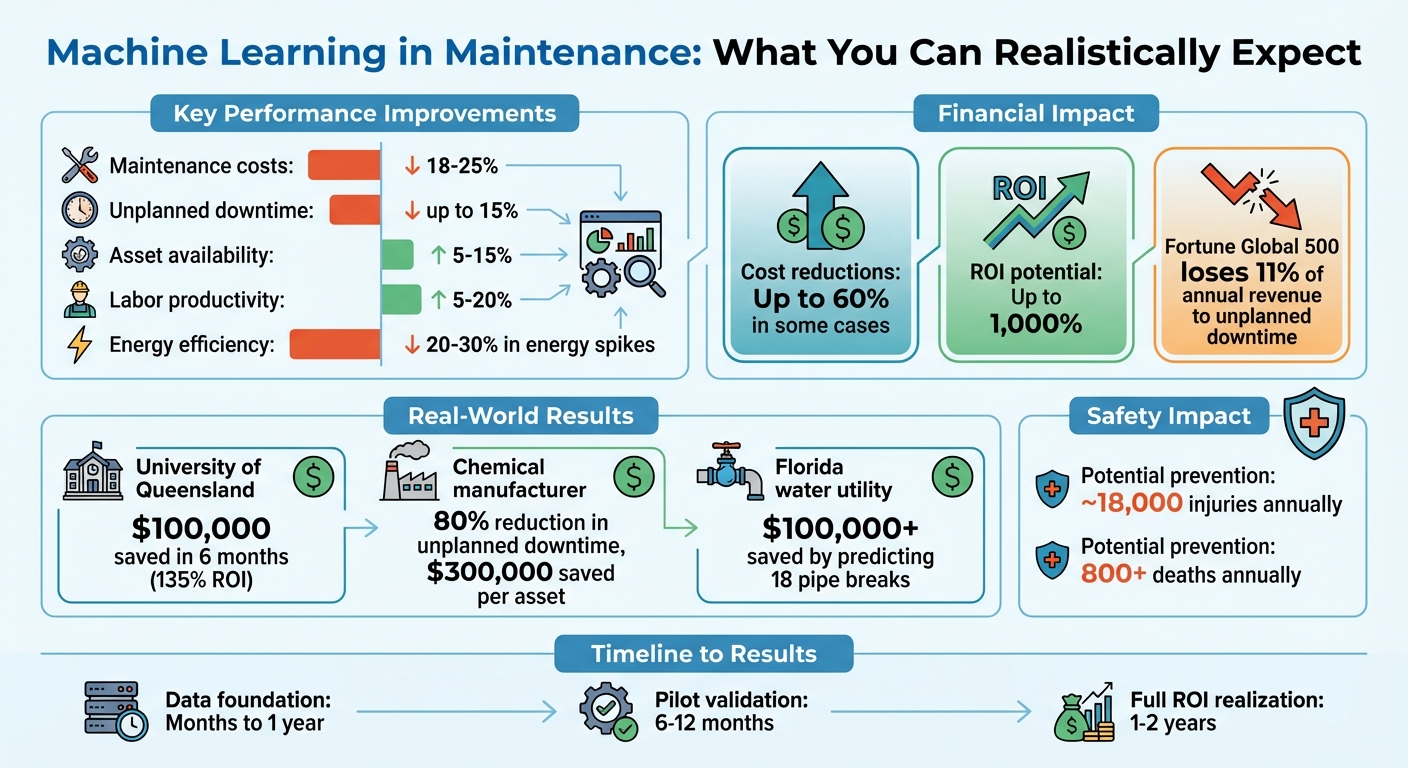
- Key Benefits: Reduces predictive vs reactive maintenance costs by 18–25%, minimizes unplanned downtime by up to 15%, boosts asset availability by 5–15%, and enhances labor productivity by 5–20%.
- How It Works: Uses sensor data and historical logs to analyze equipment health, flagging potential problems early.
- Real-World Results: Examples include the University of Queensland saving $100,000 in six months by using predictive maintenance on HVAC systems.
- Challenges: Requires high-quality data, collaboration across teams, and addressing false alarms to ensure trust in predictions.
Machine learning isn’t a quick fix but, when implemented thoughtfully, it can deliver measurable improvements and long-term savings.
Machine Learning in Maintenance: Key Benefits and Performance Metrics
What Machine Learning in Maintenance Can Actually Deliver
Main Benefits and Improvements
Machine learning transforms maintenance from a routine expense into a strategic advantage. By spotting failure patterns early, it allows for scheduled repairs and helps extend the lifespan of assets by preventing cascading failures. It also improves energy efficiency by identifying resource-wasting operations, cutting energy spikes by 20–30%. On top of that, it enhances workplace safety by automating high-risk alerts, which can reduce technician injuries and save lives. According to estimates, these advancements could potentially prevent around 18,000 injuries and over 800 deaths annually related to machinery maintenance and operations [2][8].
These benefits aren’t just theoretical – they translate into real, measurable performance boosts.
Typical Performance Improvements and Metrics
Implementing machine learning in maintenance has shown impressive results. Maintenance costs can drop by 18–25%, unplanned downtime can decrease by up to 15%, asset availability can rise by 5–15%, and labor productivity can improve by 5–20%. In some cases, cost reductions have reached as high as 60% [1][6][7][8].
Even small improvements can lead to significant savings. For instance, the Fortune Global 500 loses about 11% of its annual revenue to unplanned downtime [8]. Predictive maintenance, powered by machine learning, has been estimated to offer a return on investment (ROI) of up to 1,000% [1]. However, the actual ROI depends on factors like the criticality of the assets, the cost of failures, and how well the predictive insights are integrated into daily workflows.
The impact becomes even clearer when looking at real-world examples across different types of assets.
Real Examples from Different Asset Types
Practical applications highlight how machine learning adapts to specific asset needs. Take the University of Queensland, which implemented a predictive maintenance system in March 2016 to monitor critical equipment [10]. Machine learning algorithms tailored to asset-specific issues have proven their worth: HVAC systems use these tools to detect inefficiencies, while civil structures rely on strain and temperature data to predict maintenance requirements. These systems ensure timely, precise interventions, showcasing the tangible value of machine learning in maintenance.
sbb-itb-5be7949
What You Need Before Starting
Data Requirements and Quality Standards
To build effective machine learning models, you’ll need access to several types of data, including sensor or telemetry data (like vibration, temperature, and pressure readings), historical maintenance logs (covering past failures, repairs, and operating hours), and contextual data (such as asset details, load conditions, and external factors).
It’s crucial that your sensor data is consistent, free of noise, and recorded with synchronized timestamps and standardized units. Without the right context – like understanding whether a temperature spike is the result of a fault or a planned operational change – your raw data could lead to misleading results, such as high false-positive rates. To avoid this, ensure your data follows uniform standards across your entire asset portfolio.
Another key consideration is having enough labeled failure events for your models to learn from. If such events are rare, you might need to explore unsupervised anomaly detection instead. Check your sensor coverage against known failure modes – for example, using ISO 17359 as a guideline – and aim for at least 80% accuracy, completeness, and consistency in your data before moving forward with pilots [12]. Once your data meets these quality standards, you can focus on building the technical framework that will support your system.
Technical and Organizational Requirements
Your technical setup should include components like edge gateways for protocol translation, a unified hybrid data platform, and analytics tools (e.g., Spark or Python). These systems should be able to integrate predictions directly into your Enterprise Asset Management (EAM) or Computerized Maintenance Management Systems (CMMS), enabling automated work order generation.
On the organizational side, success depends on collaboration across teams. For example, data scientists need to work closely with reliability engineers and service experts to validate model outputs and confirm their practicality. Clearly defining roles and responsibilities is also critical – someone must take ownership of AI-generated alerts and the actions that follow. Management plays a key role here by visibly supporting data-driven decision-making and encouraging new workflows. As McKinsey highlights:
"Change management that puts the user at the center of the implementation is the single most critical success factor to ensure adoption at scale" [5].
Additionally, aligning your maintenance strategy with ISO 55001 standards can help ensure that machine learning efforts support broader asset management goals and risk-based planning. A well-designed infrastructure will not only enable smooth deployment of your models but also allow predictions to integrate seamlessly into your maintenance processes. Once your systems are in place, the next step is to evaluate your readiness through thorough data and organizational assessments.
How to Evaluate Your Readiness
Start by auditing your data infrastructure. Consolidate and standardize information from sources like CMMS, SCADA systems, and even spreadsheets. Keep in mind that 60% of AI success depends on the readiness of your data [12]. If your data quality isn’t up to par, consider implementing a data governance framework. Tools like a data catalog and assigning clear ownership for data management can provide a solid foundation.
Next, evaluate your organization’s maturity level. Are you currently reactive (fixing issues after they occur), preventive (following a fixed schedule), or condition-based (responding to specific thresholds)? Establishing this baseline will help you set realistic goals and show how machine learning can improve your existing maintenance strategy. Decide whether to invest in upskilling your current team or bringing in external experts to fill any gaps.
When launching a pilot, focus on assets that experience frequent failures rather than those that are simply the most critical. This approach gives you more data for validating your models. For instance, a large chemical manufacturer piloted predictive analytics on its extruders, leading to an 80% reduction in unplanned downtime and saving about $300,000 per asset [13]. Identifying assets with high downtime costs and clear failure patterns in your data can help demonstrate ROI early, paving the way for broader implementation.
How to Implement Machine Learning in Maintenance
Implementation Stages
Introducing machine learning into maintenance involves a step-by-step process, starting with building a solid foundation for your data. This means standardizing sensor tags, integrating IT and OT systems, and storing time-series data on a reliable platform like a governed lakehouse or hybrid system [11]. A well-organized data backbone lays the groundwork for successful pilots and smooth scaling.
The next step is running a pilot program with a specific asset category. Focus on equipment with clear failure patterns and a documented history, rather than your most critical assets. For example, the U.S. Army Materiel Command tested a "Predictive Asset Readiness" solution on selected weapon systems. Using recurrent neural networks, the system forecasted mission readiness and helped planners fine-tune maintenance schedules and inventory levels [14]. A pilot like this validates your approach and builds confidence before rolling it out on a larger scale.
Once the pilot succeeds, expand the solution across your portfolio using templates for asset classes. These templates act as reusable guides, making it easier to integrate new equipment without starting from scratch [11]. After deployment, ongoing model oversight becomes a priority to maintain accuracy and reliability.
Managing Machine Learning Models Over Time
Machine learning models need continuous care – they’re not a "set it and forget it" solution. As assets age and conditions change, models can lose accuracy. Start by monitoring for data drift, which includes changes in input-output relationships, sensor readings, or feature patterns [15]. Statistical tests like the Kolmogorov-Smirnov or Chi-square tests can help spot significant deviations [15].
Striking the right balance between precision and recall is crucial. Too many false alarms can frustrate technicians and undermine trust. McKinsey highlights this challenge:
"A model that generates numerous alarms may catch all the failures (high recall), but it is often incorrect and may not be trusted (low precision)" [5].
To address this, bring together data scientists, reliability engineers, and field technicians to fine-tune the models. Close the loop by ensuring technicians report back on work results and failure outcomes. This feedback improves model accuracy over time and helps tackle rare failure modes that emerge as equipment ages [5]. For scenarios with limited historical data, Generative Adversarial Networks (GANs) can create synthetic training data to fill the gaps [4]. Reliable models, backed by real-world data, can then directly influence operational decisions.
Connecting Predictions to Maintenance Operations
The final step is embedding these predictions into everyday maintenance workflows. Integrate model outputs into your CMMS or EAM systems to automatically generate work orders. Include sensor data, recommended actions, and lead times to streamline processes and eliminate manual handoffs [11][14].
For instance, the F-35 Joint Program Office developed the Artificial Intelligence Prognostic Steering Tool (AIPS) to manage repairs across its aircraft fleet. This tool uses machine learning to prioritize maintenance tasks, forecast failures, and optimize supply chain performance, ultimately reducing downtime and boosting efficiency [14]. Your implementation should follow a similar approach: ensure predictions lead to specific actions in the field, and feed lessons learned back into a shared knowledge base.
As Cloudera points out:
"If technicians do not trust the alerts, they will ignore them. Integrate predictions into familiar workflows and measure adoption, not just precision" [11].
To encourage adoption, deploy "super users" who can champion the solution and help their peers adapt to new processes [4]. Beyond daily operations, machine learning insights can inform long-term capital and operational planning. Use predicted failure patterns to guide multi-year investment decisions, optimize inventory, and support budget requests with solid data. This approach transforms machine learning from a tactical tool into a strategic resource for managing your entire portfolio.
Limitations and What to Expect
Technical and Data Limitations
Machine learning shows potential in maintenance, but predicting failures isn’t straightforward because breakdowns are rare. This means datasets are often skewed toward normal operations, making it tough to train models that can reliably forecast failures [16][1]. Chi-Guhn Lee, Director of the Centre for Maintenance Optimization and Reliability Engineering, highlights this issue:
"One of the unique issues with maintenance applications of machine learning is that the data size tends to be smaller than typical machine learning applications due to relatively rare failure events" [16].
Adding to the challenge is poor data quality. Maintenance logs are frequently recorded manually, which can lead to incomplete or inaccurate records of past failures [4]. Even when sensor data is available, it’s not always straightforward. Identical equipment, such as pumps, can perform differently based on factors like installation or environmental conditions, making it hard to apply the same model across all assets [1].
Another problem is the lack of detailed data. Many datasets don’t include critical information like equipment type, manufacturer, installation date, or operating conditions [16]. Sensors themselves may malfunction, provide inconsistent readings, or be entirely absent on older machines. Building dependable data pipelines from edge devices to cloud systems remains a technical headache [3].
But the challenges aren’t purely technical – organizational practices also play a significant role in the success of machine learning in maintenance.
Organizational and Process Challenges
The real obstacles often come down to people and processes, not the technology. Resistance to change is common when introducing machine learning. Maintenance teams might see algorithm-driven recommendations as a threat to their expertise or job security. Without clear communication from leadership about the benefits, adoption can stall [7]. These human factors can undermine potential improvements in efficiency and cost savings.
On top of that, many companies face skill shortages. The specialized talent needed – such as data scientists, machine learning engineers, and reliability experts – is often missing [5][13].
Another issue is false positive fatigue. If a model generates too many incorrect alerts, technicians may start ignoring warnings, even valid ones. McKinsey explains:
"A model that generates numerous alarms may catch all the failures (high recall), but it is often incorrect and may not be trusted (low precision)" [5].
Legacy equipment also poses hurdles. Older machines might need expensive retrofitting with sensors to be included in a digital maintenance system. Even if predictions are generated, integrating them with existing CMMS or EAM systems can be tricky. If these predictions don’t seamlessly translate into actionable work orders, the system risks becoming more of a burden than a benefit.
Once technical and organizational challenges are addressed, the next step is understanding the timeline and potential returns.
ROI and Timeframes
Predictive maintenance has the potential to cut costs by up to 60% and improve equipment effectiveness beyond 90%, but these gains take time [1]. Early models often generate false alarms, requiring continuous refinement to improve accuracy [5]. It can take months, or even a year, before models operate reliably.
The ROI calculation must also factor in false positives. For example, a 10% false-positive rate could lead to enough unnecessary maintenance to cancel out the savings from correctly predicted failures [7]. Harold Brink, a partner at McKinsey & Company, cautions:
"While predictive maintenance can generate substantial savings in the right circumstances, in too many cases such savings are offset by the cost of unavoidable false positives" [7].
When ROI does materialize, it comes from multiple areas: avoiding failures, delaying capital expenses, cutting unplanned downtime (often by 20% to 40%), and reducing total ownership costs by about 10% [4].
For instance, the University of Queensland outfitted 22 chiller units with IoT sensors in March 2016. Within six months, they achieved a 135% return on investment, saving around $100,000 in repair costs by preventing breakdowns [9]. Similarly, Voda AI helped a Florida water utility assess over 1,200 pipes, successfully predicting 18 avoidable breaks and saving more than $100,000 in reactive maintenance costs [9].
To maximize ROI, it’s critical to prioritize high-value assets – those with robust sensor coverage and a documented failure history. These tend to deliver the best returns. For assets with limited data or unpredictable failure patterns, simpler methods like condition-based monitoring might offer better results with less complexity [7]. Starting with pilot projects to demonstrate value before scaling across the organization is often the best approach. Focusing on critical assets and integrating predictive insights into daily workflows ensures long-term success [14][3].
Predictive Maintenance and More: How to Use Machine Learning Without Being a Data Scientist
Conclusion: Making Machine Learning Work for Your Maintenance Strategy
Machine learning has the potential to significantly improve maintenance outcomes – cutting unplanned downtime by 20–40%, reducing total ownership costs by 10%, and lowering maintenance expenses by 18–25% [4][6]. But achieving these results isn’t just about installing sensors or implementing algorithms. It requires a thoughtful, phased approach.
Start by prioritizing assets that have the greatest impact on operations, safety, or production when they fail. Focus on equipment that already has sufficient sensor coverage and a well-documented history of failures. Before expanding efforts, validate the return on investment (ROI) for high-value assets. This method not only builds confidence within your organization but also provides concrete evidence to support further investment [3][14].
Next, ensure machine learning integrates seamlessly into your operational processes. Predictive alerts should connect directly to work management systems, allowing for immediate and actionable maintenance responses [5]. Collaboration between data scientists and maintenance engineers is key, ensuring that recommendations are both practical and aligned with real-world operations [5][7]. To foster trust and ensure smooth adoption, involve technicians early, provide clear role definitions, and offer ongoing training opportunities [4][5].
To aid in this transition, the Oxand Simeo™ platform can be a valuable tool. With over 10,000 proprietary aging models and 30,000 maintenance guidelines developed over two decades, this model-driven platform helps organizations plan multi-year CAPEX and OPEX within budget, energy, and carbon constraints. By shifting from reactive maintenance to risk-based asset investment planning, Oxand Simeo™ delivers 10–25% cost savings on targeted components, extends asset lifespans, and supports compliance with ISO 55001 standards.
With a clear strategy, realistic goals, and a focus on high-impact assets, machine learning can revolutionize how you maintain and invest in your infrastructure.
FAQs
What kind of data is needed to use machine learning for maintenance?
To implement machine learning in maintenance effectively, having accurate and dependable data is crucial. Begin with high-quality sensor data that captures the physical condition of assets, such as vibration levels, temperature (measured in °F), and pressure. This data should be as clean as possible – free from excessive noise or errors – because inaccuracies can severely affect the performance of your machine learning models.
Your dataset should also be broad and well-rounded, incorporating historical failure records, maintenance logs, operational details (like load capacities or shift schedules), and external factors like environmental conditions. Consistency matters too. Use standardized measurement units (such as imperial for U.S.-based facilities), ensure timestamps follow a uniform format, and include clear metadata to identify the sources of your data.
Additionally, your organization must have the infrastructure to collect, store, and process large volumes of data in real-time or near real-time. This capability is vital for machine learning models to provide accurate, timely predictions. Establishing strong data governance practices will help maintain the quality and availability of your data over the long term.
How can organizations address resistance to adopting machine learning in maintenance?
To address resistance effectively, start by securing strong leadership support and presenting a clear business case. Highlight measurable outcomes, like annual cost savings in dollars or hours of reduced downtime. A small pilot project on a single system can be a game-changer – demonstrating quick wins, such as a 10% reduction in unplanned outages, can go a long way in building trust and confidence within the team.
Getting maintenance staff involved early is equally important. Encourage their participation in tasks like data collection, labeling events, and hands-on tool training. When employees see their expertise being valued and understand that the technology is designed to enhance their work – not replace it – concerns about job security often diminish.
Lastly, incorporate change-management strategies into your rollout. Designate team champions, set clear goals (e.g., $50,000 in maintenance savings by December 31, 2026), and celebrate milestones along the way. Keep communication open and consistent, emphasizing how machine learning can improve safety, boost equipment reliability, and streamline efficiency. This approach helps nurture a workplace culture that embraces innovation and teamwork.
What factors impact the ROI of using machine learning for predictive maintenance?
The return on investment (ROI) of a machine-learning-driven predictive maintenance program hinges on several critical factors. First and foremost, high-quality data is a must. Reliable predictions depend on data that is accurate, clean, and comprehensive, as this helps minimize false alarms and ensures the system performs effectively. Equally important is the performance of the predictive algorithms. The more precise these models are, the better they can prevent unexpected failures, cut down on spare part costs, and reduce emergency repair needs.
Another key element is the seamless integration with existing maintenance systems. Without this, valuable insights may not translate into actionable steps. The expertise of the maintenance team also plays a significant role. Skilled personnel are essential for interpreting the data, scheduling interventions, and fine-tuning the predictive models to ensure ongoing success. Lastly, aligning the program with broader business objectives – like minimizing downtime, optimizing labor, and increasing equipment availability – has a direct impact on the financial outcomes.
When these factors are effectively addressed, the savings can be substantial. Many organizations report ROI figures of 200% or more. For instance, reducing unplanned downtime – which can cost thousands of dollars per minute – paired with lower maintenance costs and enhanced productivity, makes the financial benefits of predictive maintenance not only measurable but also highly impactful.
Related Blog Posts
- Predictive vs Reactive Maintenance: Cost Analysis Guide
- Predictive Maintenance for Asset Management (Infrastructure and Real Estate) is critical – use the web site the web site:https://theiam.org
- How predictive maintenance (without IOT and real time) brings value to infrastructure and building asset owners
- Predictive Maintenance & ROI