







El aprendizaje automático está transformando el mantenimiento al predecir los problemas antes de que se produzcan, reducir los costes y mejorar la fiabilidad de los activos. Esto es lo que hay que saber:
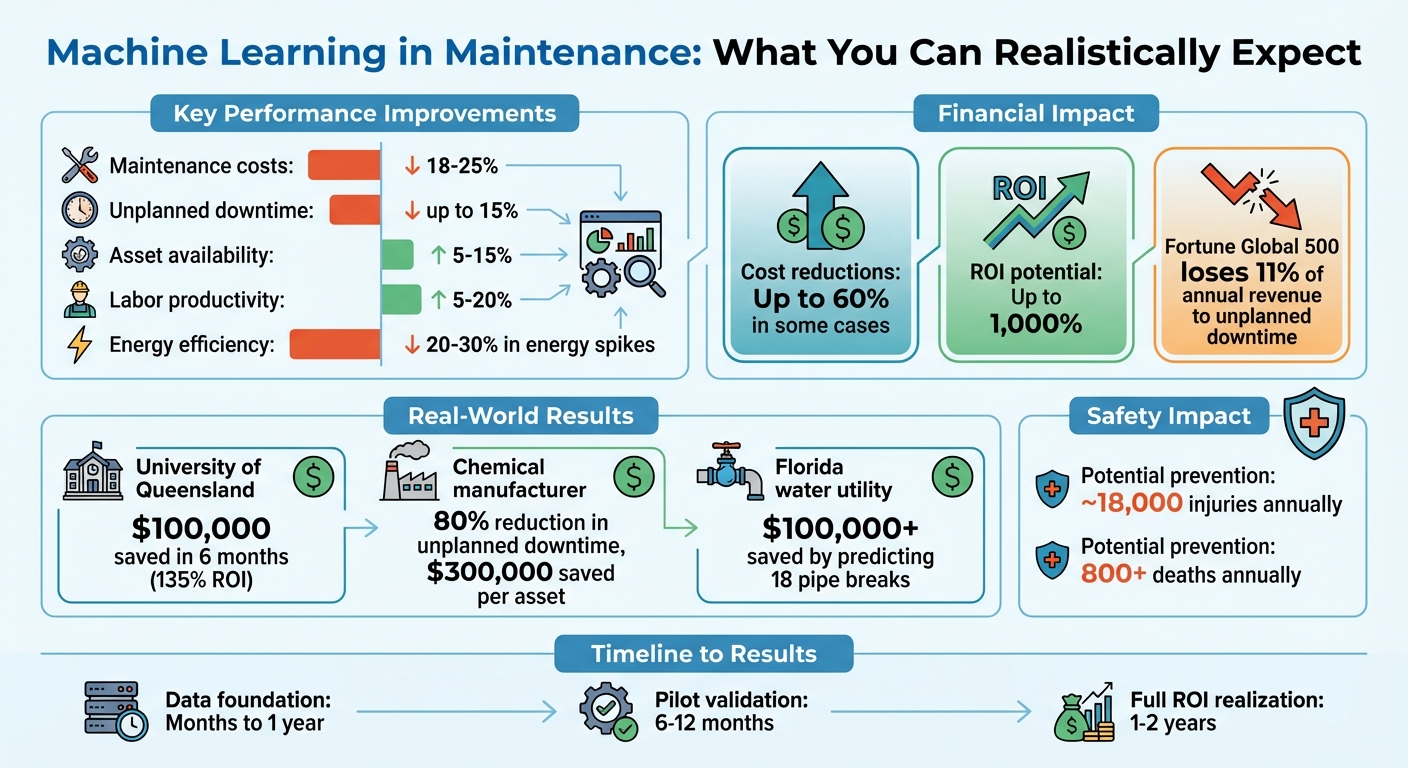
- Principales ventajas: Reduce costes de mantenimiento predictivo frente a reactivo en 18-25%, minimiza el tiempo de inactividad no planificado en hasta 15%, aumenta la disponibilidad de los activos en 5-15% y mejora la productividad laboral en 5-20%.
- Cómo funciona: Utiliza datos de sensores y registros históricos para analizar el estado de los equipos y detectar posibles problemas con antelación.
- Resultados reales: Algunos ejemplos son Universidad de Queensland ahorro de $100.000 en seis meses gracias al mantenimiento predictivo de los sistemas de calefacción, ventilación y aire acondicionado.
- Desafíos: Requiere datos de alta calidad, colaboración entre equipos y hacer frente a las falsas alarmas para garantizar la confianza en las predicciones.
El aprendizaje automático no es una solución rápida, pero si se aplica con cuidado puede aportar mejoras cuantificables y ahorros a largo plazo.
Aprendizaje automático en mantenimiento: Beneficios clave y métricas de rendimiento
Qué puede aportar realmente el aprendizaje automático en el mantenimiento
Principales ventajas y mejoras
El aprendizaje automático transforma el mantenimiento de un gasto rutinario en una ventaja estratégica. Al detectar patrones de fallo con antelación, permite programar reparaciones y ayuda a prolongar la vida útil de los activos evitando fallos en cascada. También mejora la eficiencia energética al identificar las operaciones que malgastan recursos, reduciendo los picos de energía en un 20-30%. Además, mejora la seguridad en el lugar de trabajo automatizando las alertas de alto riesgo, lo que puede reducir las lesiones de los técnicos y salvar vidas. Según las estimaciones, estos avances podrían evitar unas 18.000 lesiones y más de 800 muertes al año relacionadas con el mantenimiento y el funcionamiento de la maquinaria. [2][8].
Estas ventajas no son sólo teóricas, sino que se traducen en un aumento real y cuantificable del rendimiento.
Mejoras y métricas de rendimiento típicas
La aplicación del aprendizaje automático al mantenimiento ha dado resultados impresionantes. Los costes de mantenimiento pueden reducirse entre 18 y 25%, el tiempo de inactividad no planificado puede disminuir hasta 15%, la disponibilidad de los activos puede aumentar entre 5 y 15% y la productividad laboral puede mejorar entre 5 y 20%. En algunos casos, las reducciones de costes han llegado hasta 60%. [1][6][7][8].
Incluso las pequeñas mejoras pueden suponer ahorros significativos. Por ejemplo, la lista Fortune Global 500 pierde alrededor de 11% de sus ingresos anuales por tiempos de inactividad no planificados. [8]. Se calcula que el mantenimiento predictivo, impulsado por el aprendizaje automático, ofrece un retorno de la inversión (ROI) de hasta 1.000% [1]. Sin embargo, el ROI real depende de factores como la criticidad de los activos, el coste de los fallos y lo bien que se integren los conocimientos predictivos en los flujos de trabajo diarios.
El impacto se hace aún más evidente cuando se examinan ejemplos reales de distintos tipos de activos.
Ejemplos reales de distintos tipos de activos
Las aplicaciones prácticas ponen de relieve cómo el aprendizaje automático se adapta a las necesidades específicas de los activos. Tomemos como ejemplo la Universidad de Queensland, que implantó un sistema de mantenimiento predictivo en marzo de 2016 para supervisar equipos críticos [10]. Los algoritmos de aprendizaje automático adaptados a problemas específicos de los activos han demostrado su utilidad: Los sistemas de calefacción, ventilación y aire acondicionado utilizan estas herramientas para detectar ineficiencias, mientras que las estructuras civiles se basan en datos de tensión y temperatura para predecir las necesidades de mantenimiento. Estos sistemas garantizan intervenciones oportunas y precisas, mostrando el valor tangible del aprendizaje automático en el mantenimiento.
sbb-itb-5be7949
Lo que necesita antes de empezar
Requisitos de datos y normas de calidad
Para crear modelos de aprendizaje automático eficaces, necesitará acceder a varios tipos de datos, incluidos datos de sensores o telemetría (como lecturas de vibración, temperatura y presión), registros históricos de mantenimiento (que abarcan averías, reparaciones y horas de funcionamiento anteriores) y datos contextuales (como detalles de los activos, condiciones de carga y factores externos).
Es fundamental que los datos de los sensores sean coherentes, no tengan ruido y se registren con marcas de tiempo sincronizadas y unidades normalizadas. Sin el contexto adecuado, como saber si un pico de temperatura se debe a una avería o a un cambio operativo planificado, los datos sin procesar pueden dar lugar a resultados engañosos, como altos índices de falsos positivos. Para evitarlo, asegúrese de que sus datos siguen normas uniformes en toda su cartera de activos.
Otra consideración clave es disponer de suficientes eventos de fallo etiquetados para que sus modelos aprendan de ellos. Si este tipo de eventos son poco frecuentes, es posible que tenga que explorar la detección de anomalías sin supervisión. Compruebe la cobertura de su sensor en función de los modos de fallo conocidos, por ejemplo, mediante ISO 17359 como directriz - y aspire a que sus datos sean al menos 80% precisos, completos y coherentes antes de seguir adelante con los proyectos piloto. [12]. Una vez que sus datos cumplan estas normas de calidad, podrá centrarse en crear el marco técnico que sustentará su sistema.
Requisitos técnicos y organizativos
Su configuración técnica debe incluir componentes como pasarelas de borde para la traducción de protocolos, una plataforma unificada de datos híbridos y herramientas de análisis (por ejemplo, Spark o Python). Estos sistemas deben ser capaces de integrar las predicciones directamente en sus sistemas de gestión de activos empresariales (EAM) o de gestión del mantenimiento informatizado (CMMS), permitiendo la generación automática de órdenes de trabajo.
Desde el punto de vista organizativo, el éxito depende de la colaboración entre equipos. Por ejemplo, los científicos de datos deben colaborar estrechamente con ingenieros de fiabilidad y expertos en servicios para validar los resultados de los modelos y confirmar su viabilidad. También es fundamental definir claramente las funciones y responsabilidades: alguien debe responsabilizarse de las alertas generadas por la IA y de las acciones subsiguientes. La dirección desempeña aquí un papel clave, apoyando visiblemente la toma de decisiones basada en datos y fomentando nuevos flujos de trabajo. Como McKinsey destacados:
"Una gestión del cambio que sitúe al usuario en el centro de la implantación es el factor de éxito más crítico para garantizar la adopción a escala" [5].
Además, alinear su estrategia de mantenimiento con ISO 55001 pueden ayudar a garantizar que los esfuerzos de aprendizaje automático respalden objetivos más amplios de gestión de activos y planificación basada en riesgos. Una infraestructura bien diseñada no solo facilitará el despliegue de sus modelos, sino que también permitirá que las predicciones se integren a la perfección en sus procesos de mantenimiento. Una vez implantados los sistemas, el siguiente paso es evaluar su preparación mediante evaluaciones exhaustivas de los datos y la organización.
Cómo evaluar su preparación
Empiece por auditar su infraestructura de datos. Consolide y estandarice la información procedente de fuentes como GMAO, sistemas SCADA e incluso hojas de cálculo. Tenga en cuenta que 60% del éxito de la IA depende de la preparación de sus datos. [12]. Si la calidad de sus datos no está a la altura, considere la posibilidad de implantar un marco de gobernanza de datos. Herramientas como un catálogo de datos y la asignación de una propiedad clara para la gestión de datos pueden proporcionar una base sólida.
A continuación, evalúe el nivel de madurez de su organización. ¿Actualmente es reactiva (soluciona los problemas después de que se produzcan), preventiva (sigue un programa fijo) o basada en condiciones (responde a umbrales específicos)? Establecer esta línea de base le ayudará a fijar objetivos realistas y a mostrar cómo el aprendizaje automático puede mejorar su estrategia de mantenimiento actual. Decida si invierte en mejorar las competencias de su equipo actual o en contratar a expertos externos para cubrir las carencias.
Cuando ponga en marcha un proyecto piloto, céntrese en los activos que experimentan fallos frecuentes en lugar de en los que son simplemente los más críticos. Este enfoque le proporciona más datos para validar sus modelos. Por ejemplo, un gran fabricante de productos químicos puso a prueba el análisis predictivo en sus extrusoras, lo que le permitió reducir en 80% los tiempos de inactividad imprevistos y ahorrar unos $300.000 por activo. [13]. La identificación de activos con elevados costes de inactividad y patrones de fallo claros en sus datos puede ayudar a demostrar la rentabilidad de la inversión en una fase temprana, allanando el camino para una implantación más amplia.
Cómo implantar el aprendizaje automático en el mantenimiento
Etapas de aplicación
Introducir el aprendizaje automático en el mantenimiento implica un proceso paso a paso, empezando por construir una base sólida para sus datos. Esto significa estandarizar las etiquetas de los sensores, integrar los sistemas de IT y OT, y almacenar los datos de series temporales en una plataforma fiable, como un lago gobernado o un sistema híbrido... [11]. Una base de datos bien organizada sienta las bases para el éxito de los proyectos piloto y una ampliación sin problemas.
El siguiente paso es ejecutar un programa piloto con una categoría de activos específica. Céntrese en equipos con patrones de fallo claros y un historial documentado, en lugar de en sus activos más críticos. Por ejemplo, el Mando de Material del Ejército de Estados Unidos probó una solución de "preparación predictiva de activos" en determinados sistemas de armas. Utilizando redes neuronales recurrentes, el sistema predijo la disponibilidad de la misión y ayudó a los planificadores a ajustar los programas de mantenimiento y los niveles de inventario. [14]. Un proyecto piloto de este tipo valida su enfoque y genera confianza antes de ponerlo en marcha a mayor escala.
Una vez que el piloto tenga éxito, amplíe la solución a toda su cartera utilizando plantillas por clases de activos. Estas plantillas actúan como guías reutilizables, facilitando la integración de nuevos equipos sin empezar desde cero [11]. Tras la implantación, la supervisión continua del modelo se convierte en una prioridad para mantener su precisión y fiabilidad.
Gestión de modelos de aprendizaje automático a lo largo del tiempo
Los modelos de aprendizaje automático requieren un cuidado continuo: no son una solución de "configúralo y olvídate". A medida que los activos envejecen y las condiciones cambian, los modelos pueden perder precisión. Empiece por vigilar la deriva de los datos, que incluye cambios en las relaciones de entrada-salida, lecturas de sensores o patrones de características. [15]. Pruebas estadísticas como las de Kolmogorov-Smirnov o Chi-cuadrado pueden ayudar a detectar desviaciones significativas. [15].
Lograr el equilibrio adecuado entre precisión y capacidad de recuperación es crucial. Demasiadas falsas alarmas pueden frustrar a los técnicos y minar la confianza. McKinsey destaca este reto:
"Un modelo que genera numerosas alarmas puede captar todos los fallos (recall alto), pero a menudo es incorrecto y puede no ser de fiar (precisión baja)" [5].
Para ello, reúna a científicos de datos, ingenieros de fiabilidad y técnicos de campo para ajustar los modelos. Cierre el bucle asegurándose de que los técnicos informan sobre los resultados del trabajo y los fallos. Esta información mejora la precisión del modelo a lo largo del tiempo y ayuda a abordar los modos de fallo poco frecuentes que surgen a medida que los equipos envejecen. [5]. Para escenarios con datos históricos limitados, las Redes Generativas Adversariales (GAN) pueden crear datos de entrenamiento sintéticos para llenar los vacíos. [4]. Los modelos fiables, respaldados por datos reales, pueden influir directamente en las decisiones operativas.
Conectar las predicciones con las operaciones de mantenimiento
El último paso consiste en integrar estas predicciones en los flujos de trabajo cotidianos de mantenimiento. Integre los resultados del modelo en sus sistemas GMAO o EAM para generar automáticamente órdenes de trabajo. Incluya datos de sensores, acciones recomendadas y plazos de entrega para agilizar los procesos y eliminar las transferencias manuales. [11][14].
Por ejemplo, el Oficina del Programa Conjunto del F-35 desarrolló la Herramienta de Dirección de Pronóstico de Inteligencia Artificial (AIPS) para gestionar las reparaciones en toda su flota de aviones. Esta herramienta utiliza el aprendizaje automático para priorizar las tareas de mantenimiento, prever fallos y optimizar el rendimiento de la cadena de suministro, reduciendo en última instancia el tiempo de inactividad y aumentando la eficiencia. [14]. Su aplicación debe seguir un planteamiento similar: garantizar que las predicciones se traduzcan en acciones concretas sobre el terreno, e incorporar las lecciones aprendidas a una base de conocimientos compartida.
En Cloudera señala:
"Si los técnicos no confían en las alertas, las ignorarán. Integre las predicciones en flujos de trabajo conocidos y mida la adopción, no solo la precisión"." [11].
Para fomentar la adopción, despliegue "superusuarios" que puedan defender la solución y ayudar a sus compañeros a adaptarse a los nuevos procesos. [4]. Más allá de las operaciones diarias, los conocimientos de aprendizaje automático pueden servir de base para la planificación operativa y de capital a largo plazo. Utilice los patrones de fallos previstos para orientar las decisiones de inversión plurianuales, optimizar el inventario y respaldar las solicitudes presupuestarias con datos sólidos. Este enfoque transforma el aprendizaje automático de una herramienta táctica en un recurso estratégico para gestionar toda su cartera.
Limitaciones y expectativas
Limitaciones técnicas y de datos
El aprendizaje automático tiene potencial para el mantenimiento, pero predecir fallos no es sencillo porque las averías son poco frecuentes. Esto significa que los conjuntos de datos suelen estar sesgados hacia el funcionamiento normal, lo que dificulta el entrenamiento de modelos capaces de predecir fallos de forma fiable. [16][1]. Chi-Guhn Lee, Director del Centro de Optimización del Mantenimiento e Ingeniería de la Fiabilidad, destaca esta cuestión:
"Uno de los problemas exclusivos de las aplicaciones de mantenimiento del aprendizaje automático es que el tamaño de los datos tiende a ser menor que el de las aplicaciones típicas de aprendizaje automático debido a que los eventos de fallo son relativamente raros" [16].
A este reto se añade mala calidad de los datos. Con frecuencia, los registros de mantenimiento se realizan manualmente, lo que puede dar lugar a registros incompletos o inexactos de fallos anteriores. [4]. Incluso cuando se dispone de datos de sensores, no siempre es sencillo. Equipos idénticos, como las bombas, pueden funcionar de forma diferente en función de factores como la instalación o las condiciones ambientales, lo que dificulta la aplicación del mismo modelo a todos los activos. [1].
Otro problema es la falta de datos detallados. Muchos conjuntos de datos no incluyen información esencial como el tipo de equipo, el fabricante, la fecha de instalación o las condiciones de funcionamiento. [16]. Los propios sensores pueden funcionar mal, proporcionar lecturas incoherentes o estar totalmente ausentes en las máquinas más antiguas. Crear canales de datos fiables desde los dispositivos periféricos hasta los sistemas en la nube sigue siendo un quebradero de cabeza técnico. [3].
Pero los retos no son puramente técnicos: las prácticas organizativas también desempeñan un papel importante en el éxito del aprendizaje automático en el mantenimiento.
Retos organizativos y de procesos
Los verdaderos obstáculos suelen ser las personas y los procesos, no la tecnología. La resistencia al cambio es habitual cuando se introduce el aprendizaje automático. Los equipos de mantenimiento pueden ver las recomendaciones basadas en algoritmos como una amenaza para su experiencia o seguridad laboral. Sin una comunicación clara de las ventajas por parte de la dirección, la adopción puede estancarse. [7]. Estos factores humanos pueden socavar posibles mejoras de la eficiencia y el ahorro de costes.
Además, muchas empresas se enfrentan a escasez de cualificaciones. A menudo falta el talento especializado necesario, como científicos de datos, ingenieros de aprendizaje automático y expertos en fiabilidad. [5][13].
Otra cuestión es fatiga por falsos positivos. Si un modelo genera demasiadas alertas incorrectas, los técnicos pueden empezar a ignorar los avisos, incluso los válidos. McKinsey lo explica:
"Un modelo que genera numerosas alarmas puede captar todos los fallos (recall alto), pero a menudo es incorrecto y puede no ser de fiar (precisión baja)" [5].
Los equipos antiguos también plantean obstáculos. Las máquinas antiguas pueden necesitar una costosa adaptación con sensores para incluirlas en un sistema de mantenimiento digital. Incluso si se generan predicciones, su integración con los sistemas GMAO o EAM existentes puede resultar complicada. Si estas predicciones no se traducen a la perfección en órdenes de trabajo procesables, el sistema corre el riesgo de convertirse más en una carga que en una ventaja.
Una vez abordados los retos técnicos y organizativos, el siguiente paso es comprender el calendario y los posibles beneficios.
Retorno de la inversión y plazos
El mantenimiento predictivo puede reducir los costes hasta 60% y mejorar la eficacia de los equipos más allá de 90%, pero estos beneficios llevan su tiempo. [1]. Los primeros modelos suelen generar falsas alarmas, por lo que es necesario perfeccionarlos para mejorar su precisión. [5]. Pueden pasar meses, o incluso un año, antes de que los modelos funcionen de forma fiable.
El cálculo del ROI también debe tener en cuenta falsos positivos. Por ejemplo, una tasa de falsos positivos de 10% podría dar lugar a un mantenimiento innecesario suficiente para anular el ahorro derivado de la predicción correcta de fallos. [7]. Harold Brink, socio de McKinsey & Company, advierte:
"Aunque el mantenimiento predictivo puede generar ahorros sustanciales en las circunstancias adecuadas, en demasiados casos dichos ahorros se ven contrarrestados por el coste de los inevitables falsos positivos" [7].
Cuando el retorno de la inversión se materializa, procede de múltiples áreas: evitar fallos, retrasar los gastos de capital, reducir el tiempo de inactividad no planificado (a menudo entre 201 y 401 TTP3T) y reducir los costes totales de propiedad en unos 101 TTP3T. [4].
Por ejemplo, la Universidad de Queensland equipó 22 unidades de refrigeración con sensores IoT en marzo de 2016. En seis meses, lograron un 135% retorno de la inversión, Ahorro de unos $100.000 en costes de reparación gracias a la prevención de averías. [9]. Del mismo modo, Voda AI Ayudó a una empresa de suministro de agua de Florida a evaluar más de 1.200 tuberías, previniendo con éxito 18 roturas evitables y ahorrando más de $100.000 en costes de mantenimiento reactivo. [9].
Para maximizar el retorno de la inversión, es fundamental dar prioridad a los activos de alto valor - Los que cuentan con una sólida cobertura de sensores y un historial de fallos documentado. Estos suelen ofrecer los mejores resultados. Para los activos con datos limitados o patrones de fallo impredecibles, métodos más sencillos como la supervisión basada en el estado pueden ofrecer mejores resultados con menos complejidad. [7]. Empezar con proyectos piloto para demostrar su valor antes de ampliarlos a toda la organización suele ser el mejor enfoque. Centrarse en los activos críticos e integrar la información predictiva en los flujos de trabajo diarios garantiza el éxito a largo plazo. [14][3].
Mantenimiento predictivo y más: Cómo usar el aprendizaje automático sin ser un científico de datos
Conclusiones: Cómo hacer que el aprendizaje automático funcione para su estrategia de mantenimiento
El aprendizaje automático tiene el potencial de mejorar significativamente los resultados del mantenimiento, reduciendo el tiempo de inactividad no planificado en 20-40%, reduciendo los costes totales de propiedad en 10% y disminuyendo los gastos de mantenimiento en 18-25%. [4][6]. Pero para conseguir estos resultados no basta con instalar sensores o aplicar algoritmos. Requiere un planteamiento meditado y por fases.
Empiece por dar prioridad a los activos que tienen el mayor impacto en las operaciones, la seguridad o la producción cuando fallan. Céntrese en los equipos que ya tengan una cobertura de sensores suficiente y un historial de fallos bien documentado. Antes de ampliar los esfuerzos, validar el rendimiento de la inversión (ROI) para activos de alto valor. Este método no sólo genera confianza dentro de su organización, sino que también proporciona pruebas concretas para respaldar nuevas inversiones. [3][14].
A continuación, asegúrese de que el aprendizaje automático se integra perfectamente en sus procesos operativos. Las alertas predictivas deben conectarse directamente con los sistemas de gestión del trabajo, permitiendo respuestas de mantenimiento inmediatas y procesables. [5]. La colaboración entre los científicos de datos y los ingenieros de mantenimiento es clave para garantizar que las recomendaciones sean prácticas y se ajusten a las operaciones del mundo real. [5][7]. Para fomentar la confianza y garantizar una adopción sin problemas, implique a los técnicos desde el principio, defina claramente sus funciones y ofrezca oportunidades de formación continua. [4][5].
Para facilitar esta transición, la Oxand Simeo™ puede ser una herramienta valiosa. Con más de 10,000 modelos de envejecimiento propios y 30,000 pautas de mantenimiento desarrolladas a lo largo de dos décadas, esta plataforma basada en modelos ayuda a las organizaciones a planificar CAPEX y OPEX plurianuales dentro de las limitaciones presupuestarias, energéticas y de carbono. Al pasar del mantenimiento reactivo al planificación de la inversión de activos basada en el riesgo, Oxand Simeo™ ofrece ahorros de costes 10-25% en componentes específicos, amplía la vida útil de los activos y apoya el cumplimiento de las normas ISO 55001.
Con una estrategia clara, objetivos realistas y un enfoque en los activos de alto impacto, el aprendizaje automático puede revolucionar la forma de mantener e invertir en su infraestructura.
Preguntas frecuentes
¿Qué tipo de datos se necesitan para utilizar el aprendizaje automático en el mantenimiento?
Para aplicar eficazmente el aprendizaje automático en el mantenimiento, es necesario datos precisos y fiables es crucial. Comience con datos de sensores de alta calidad que capturen el estado físico de los activos, como los niveles de vibración, la temperatura (medida en °F) y la presión. Estos datos deben estar lo más limpios posible, sin ruidos ni errores excesivos, porque las imprecisiones pueden afectar gravemente al rendimiento de los modelos de aprendizaje automático.
Su conjunto de datos también debe ser amplio y completo, La coherencia también es importante, ya que permite mejorar el rendimiento de las máquinas, incorporando registros históricos de fallos, registros de mantenimiento, detalles operativos (como capacidades de carga u horarios de turnos) y factores externos como las condiciones ambientales. La coherencia también es importante. Utilice unidades de medida normalizadas (como el sistema imperial para las instalaciones con sede en EE.UU.), asegúrese de que las marcas de tiempo siguen un formato uniforme e incluya metadatos claros para identificar las fuentes de sus datos.
Además, su organización debe disponer de la infraestructura necesaria para recopilar, almacenar y procesar grandes volúmenes de datos en tiempo real o casi real. Esta capacidad es vital para que los modelos de aprendizaje automático proporcionen predicciones precisas y oportunas. Establecer prácticas sólidas de gobernanza de datos ayudará a mantener la calidad y disponibilidad de los datos a largo plazo.
¿Cómo pueden las organizaciones hacer frente a la resistencia a adoptar el aprendizaje automático en el mantenimiento?
Para hacer frente a la resistencia con eficacia, empiece por asegurarse fuerte apoyo del liderazgo y presentar un argumento empresarial claro. Destaque los resultados mensurables, como ahorro anual de costes en dólares o horas de inactividad reducidas. Un pequeño proyecto piloto en un único sistema puede cambiar las reglas del juego, demostrando ventajas rápidas, como un 10% de reducción de las interrupciones imprevistas, puede contribuir en gran medida a generar confianza en el equipo.
Conseguir que el personal de mantenimiento se implique desde el principio es igualmente importante. Fomente su participación en tareas como la recopilación de datos, los eventos de etiquetado y la formación práctica sobre herramientas. Cuando los empleados ven que se valora su experiencia y comprenden que la tecnología está diseñada para mejorar su trabajo, no para sustituirlo, las preocupaciones por la seguridad laboral suelen disminuir.
Por último, incorpore estrategias de gestión del cambio a su implantación. Designe campeones de equipo, establezca objetivos claros (por ejemplo, $50.000 de ahorro en mantenimiento para el 31 de diciembre de 2026), y celebre los hitos a lo largo del camino. Mantenga una comunicación abierta y coherente, haciendo hincapié en cómo el aprendizaje automático puede mejorar la seguridad, aumentar la fiabilidad de los equipos y agilizar la eficiencia. Este enfoque ayuda a fomentar una cultura de trabajo que abraza la innovación y el trabajo en equipo.
¿Qué factores influyen en la rentabilidad de la utilización del aprendizaje automático para el mantenimiento predictivo?
El retorno de la inversión (ROI) de un programa de mantenimiento predictivo basado en el aprendizaje automático depende de varios factores críticos. El primero y más importante, datos de calidad es imprescindible. Las predicciones fiables dependen de que los datos sean precisos, limpios y completos, ya que esto ayuda a minimizar las falsas alarmas y garantiza que el sistema funcione con eficacia. Igualmente importante es la rendimiento de los algoritmos de predicción. Cuanto más precisos sean estos modelos, mejor podrán prevenir averías inesperadas, reducir los costes en piezas de repuesto y disminuir las necesidades de reparaciones de emergencia.
Otro elemento clave es la integración perfecta con los sistemas de mantenimiento existentes. Sin esto, es posible que las ideas valiosas no se traduzcan en medidas prácticas. En experiencia del equipo de mantenimiento también desempeña un papel importante. El personal cualificado es esencial para interpretar los datos, programar las intervenciones y ajustar los modelos predictivos para garantizar el éxito continuo. Por último, alinear el programa con objetivos empresariales más amplios -como minimizar el tiempo de inactividad, optimizar la mano de obra y aumentar la disponibilidad de los equipos- tiene un impacto directo en los resultados financieros.
Cuando estos factores se abordan eficazmente, el ahorro puede ser sustancial. Muchas organizaciones informan de cifras de ROI de 200% o más. Por ejemplo, la reducción del tiempo de inactividad imprevisto, que puede costar miles de dólares por minuto, junto con la reducción de los costes de mantenimiento y la mejora de la productividad, hace que los beneficios financieros del mantenimiento predictivo no solo sean cuantificables, sino que también tengan un gran impacto.
Entradas de blog relacionadas
- Mantenimiento predictivo frente a mantenimiento reactivo: Guía de análisis de costes
- El mantenimiento predictivo para la gestión de activos (infraestructuras y bienes inmuebles) es fundamental - utilice el sitio web el sitio web:https://theiam.org
- Cómo el mantenimiento predictivo (sin IoT ni tiempo real) aporta valor a los propietarios de infraestructuras y activos de edificios
- Mantenimiento predictivo y ROI