






Poner en marcha un proyecto piloto de mantenimiento predictivo en 90 días es factible y puede dar resultados inmediatos. Este es el proceso en pocas palabras:
- Por qué es importante: El mantenimiento predictivo reduce las averías de los equipos en 70%, recorta los costes de mantenimiento en 25% y puede llegar a multiplicar por 8 el retorno de la inversión. Los tiempos de inactividad imprevistos cuestan a las organizaciones miles de millones al año, por lo que este cambio es fundamental para la eficiencia y el ahorro.
- Desafíos: Los elevados costes iniciales y el escepticismo de las partes interesadas suelen dificultar la implantación. Un proyecto piloto de 90 días resuelve estos problemas demostrando su valor rápidamente.
- Pasos para empezar:
- Días 1-30: Definir objetivos claros (por ejemplo, reducir el tiempo de inactividad o los costes), seleccionar entre 15 y 50 activos de alto impacto e implicar a las partes interesadas.
- Días 31-60: Construya una base de datos sólida mediante la creación de un inventario de activos, la recopilación de datos históricos y el establecimiento de líneas de base.
- Días 61-90: Ponga en marcha el proyecto piloto, supervise los resultados, valide las alertas y realice un seguimiento de los indicadores clave de rendimiento (KPI), como el tiempo medio entre fallos (MTBF) y el ahorro de costes.
- Métricas clave: Se centra en la fiabilidad (MTBF), la capacidad de respuesta (tiempo medio de reparación), la productividad (eficacia global de los equipos) y el impacto financiero (evitación de costes de mantenimiento).
- Resultados: Los proyectos piloto de éxito suelen descubrir problemas ocultos, evitar fracasos costosos y demostrar un claro retorno de la inversión. Por ejemplo, el Ciudad de Tulsa ahorró lo suficiente en un solo incidente para cubrir dos años de costes de servicio.
Empiece poco a poco, demuestre el valor y coja impulso hacia mejoras a largo plazo. Esta guía garantiza un enfoque estructurado y cuantificable del mantenimiento predictivo.
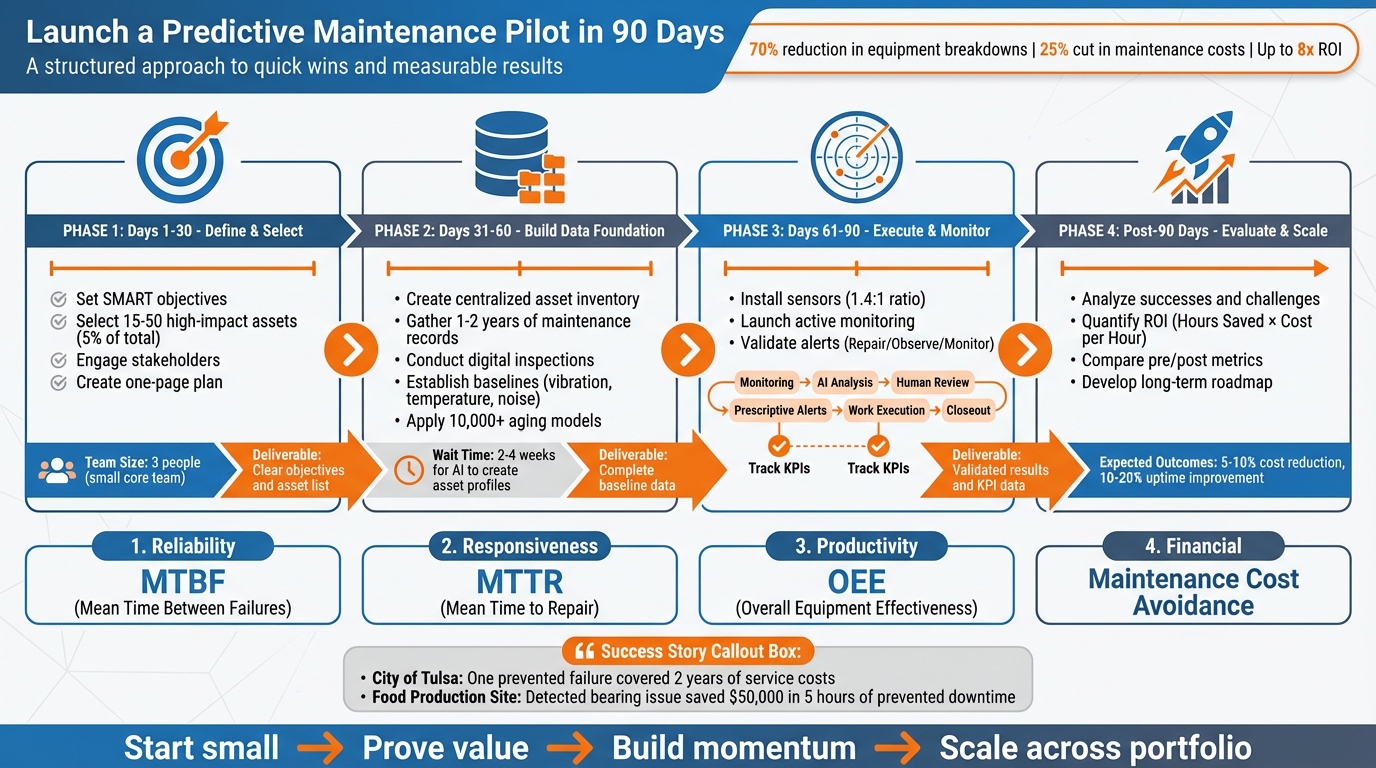
Calendario de implantación del proyecto piloto de mantenimiento predictivo en 90 días
Qué es el mantenimiento predictivo (PdM) - Cómo aplicarlo
Días 1-30: Definición de objetivos y selección de activos piloto
El primer mes consiste en preparar el terreno: definir los activos de prueba, establecer objetivos claros y determinar cómo se medirá el éxito. Mantenga un equipo reducido, de unas tres personas, para que las decisiones se tomen con rapidez y eficacia. ¿Cuál es el objetivo? Un plan sencillo, de una sola página, que todos puedan entender y apoyar.
Establecer objetivos SMART para el proyecto piloto
Empiece por identificar el "por qué" de su proyecto piloto. ¿Intenta minimizar las llamadas de emergencia en horas intempestivas, reducir los costes de mantenimiento de un tipo de activo específico o aumentar el tiempo de actividad de la producción? Sus objetivos deben responder a necesidades empresariales reales, no centrarse únicamente en la tecnología. Utilice el marco SMART para dar forma a sus objetivos:
- Específico: Diríjase a un activo o modo de fallo concreto.
- Mensurable: Utilice métricas clave como el tiempo medio antes de fallos (MTBF) o el ahorro en costes de mantenimiento.
- Realizable: Empezar con un enfoque de prueba de valor para garantizar la viabilidad.
- Correspondiente: Alinearse con las prioridades empresariales más amplias.
- Con límite de tiempo: Fije un plazo de 90 a 180 días para obtener información práctica.
Escriba una declaración concisa, de una línea, que aclare su objetivo:
"[El Departamento] debe [actuar] antes de [plazo], con [resultado] y evitando [coste del problema]"."
Por ejemplo: "El mantenimiento debe reducir el tiempo de inactividad no planificado de la máquina CNC #7 en 15% en un plazo de seis meses, ahorrando $75.000 en producción perdida y evitando costosas reparaciones de emergencia." Esta claridad no sólo agudiza su enfoque, sino que también simplifica la comunicación con las partes interesadas que aprueban presupuestos o asignan recursos.
Con unos objetivos claros, el siguiente paso es elegir los activos que mejor demuestren el valor de su proyecto piloto.
Identificar activos piloto de gran impacto
Elija activos con fallos poco frecuentes pero costosos: estos "malos actores" a menudo agotan los recursos e incluso pueden paralizar la producción. Por ejemplo, un centro de producción de alimentos controló una vez los rodamientos de su cinta transportadora y detectó niveles de vibración inusualmente altos en uno de ellos. Aunque el fallo era inaudible para el oído humano, se detectó a tiempo, lo que permitió programar las reparaciones durante el mantenimiento regular. Esta medida proactiva evitó cinco horas de paradas imprevistas, lo que supuso un ahorro de $50.000 ($10.000 por hora). Este único acontecimiento justificó inmediatamente el valor del piloto.
Seleccione entre 15 y 50 activos, aproximadamente el 5% del total de activos de su centro, para aumentar la probabilidad de capturar al menos un evento de fallo en 90 días. Céntrese en los activos que cumplan estos criterios:
- Disponga de al menos seis meses de datos históricos de mantenimiento en su GMAO para disponer de bases de referencia fiables.
- Muestran una degradación progresiva (como cambios en la vibración, el calor o el ruido) en lugar de fallos repentinos.
- Son físicamente accesibles para la instalación de sensores y tienen una conectividad de red fiable.
Implicar a las partes interesadas y definir indicadores de éxito
Una vez fijados los objetivos e identificados los activos, es hora de incorporar a las personas adecuadas. Es crucial que las partes interesadas clave se impliquen desde el principio. Los técnicos de mantenimiento pueden localizar los activos vulnerables y verificar la precisión de las alertas. El personal informático garantiza un flujo de datos fluido entre los sensores y el sistema central. Los responsables de producción alinean el piloto con los resultados empresariales, como la mejora de la eficacia general de los equipos (OEE).
Establezca KPI claros y medibles para cada grupo de interés. Por ejemplo:
- Técnicos: Reducción de las llamadas de urgencia.
- CFOs: Busque un menor gasto de mantenimiento y un claro retorno de la inversión.
- Jefes de producción: Dar prioridad a maximizar la disponibilidad de las máquinas.
- Ingenieros de fiabilidad: Seguimiento de las mejoras en MTBF y la salud general de los activos.
Antes de poner en marcha el proyecto piloto, establezca una base de referencia para estos parámetros. Esto le permitirá evaluar con precisión el impacto del proyecto piloto al final del periodo de 90 días.
Días 31-60: Construya su base de datos
Ahora que sus objetivos están claros y ha elegido los activos piloto, es el momento de centrarse en crear una base de datos sólida. En los próximos 30 días, establecerá un inventario de activos limpio, documentará las condiciones de referencia y utilizará modelos predictivos para obtener información práctica para su programa piloto.
Configure su inventario de activos con Inventario Simeo
Empiece construyendo un registro centralizado de activos para que le sirva de fuente de información sobre los activos. Este registro debe incluir detalles como el nombre de cada activo, el tipo, la ubicación, el fabricante/modelo, la fecha de instalación, el estado de la garantía, el historial de mantenimiento, la calificación del estado y cualquier documento técnico clave. [10]. Organice todo en una jerarquía clara: emplazamiento, edificio, sistema y componente. De este modo, cuando los sensores detecten un problema, podrá localizar rápidamente la parte específica que necesita atención. [9].
A continuación, reúna 1 ó 2 años de registros de mantenimiento de su GMAO, sistema EAM o diarios de los operarios. [9][5]. Estos datos históricos proporcionan un contexto para identificar los modos de fallo comunes y ayudan a establecer una base de comparación. Para su proyecto piloto, céntrese en aproximadamente 5% del total de activos de su centro. De este modo, los datos serán manejables y aumentarán las probabilidades de detectar un fallo en los primeros 90 días. [9].
Clasifique sus activos en una escala de 1 a 5 en función de factores como la seguridad, el impacto en la producción, los costes de inactividad, la frecuencia de los fallos y los plazos de reparación. [10]. Esta clasificación garantiza que sus modelos predictivos se concentren en los activos que tienen mayor impacto en sus operaciones.
Una vez realizado el inventario, el siguiente paso es documentar las condiciones de referencia.
Inspecciones y evaluaciones digitales
Utilice herramientas de inspección digital como Simeo GO establecer parámetros de funcionamiento de referencia, como los niveles de vibración, temperatura y ruido [2][11]. Estandarice la introducción de datos con sistemas de puntuación coherentes, códigos de error y plantillas digitales. [6].
"Sin datos, no se puede predecir nada. Si no tienes una línea de base sobre lo que es normal para una bomba o un transportador, no puedes identificar o predecir anomalías". - Bryan Sapot, CEO, SensrTrx [11]
Asegúrese de capturar tanto los datos numéricos como las notas contextuales, incluidas las fotos. Esta combinación proporciona una imagen completa para su posterior validación. Por ejemplo, si un sensor de vibraciones detecta una anomalía, los técnicos pueden consultar fotos de inspecciones recientes para confirmar si hay desgaste visible o desalineación. Además, verifique desde el principio que todas las herramientas digitales tienen conectividad de red activa para evitar lagunas de datos que podrían interrumpir su piloto. [4].
Con sus datos de referencia, está listo para pasar al modelado predictivo.
Aplicar modelos predictivos y leyes de mantenimiento
Ahora es el momento de poner a trabajar sus datos de inventario limpios y sus condiciones de referencia. Plataformas como Oxand utilizar una biblioteca de Más de 10.000 modelos envejecidos y Más de 30.000 leyes de mantenimiento desarrollados a partir de décadas de experiencia en el mundo real. Estos modelos simulan la degradación de los activos, calculan la vida útil restante (RUL) y señalan las desviaciones del rendimiento normal. [7].
Empiece con el Análisis de Modos de Fallo y Efectos (AMFE) para priorizar los modos de fallo de alto riesgo. Esto implica calcular un Número de Prioridad de Riesgo (RPN) basado en la gravedad, la frecuencia y la detectabilidad. [7]. De este modo, se asegura de que sus algoritmos predictivos se centran en los riesgos más críticos para la seguridad, la producción o los costes.
Utilice modelos de detección de anomalías para detectar desviaciones respecto a las líneas de base establecidas. Los sistemas de IA suelen tardar entre dos y cuatro semanas en crear perfiles operativos únicos para cada activo. [4]. Durante este periodo, combine los conocimientos de la IA con las aportaciones de técnicos experimentados para eliminar los falsos positivos y confirmar que las alertas son procesables. [6]. Por ejemplo, un importante fabricante de automóviles logró una precisión de 94% en la predicción de fallos, evitando costosos tiempos de inactividad imprevistos. [8].
sbb-itb-5be7949
Días 61-90: Ejecutar el proyecto piloto y medir los resultados
Con el marco de datos listo, los últimos 30 días se dedican a poner en marcha el proyecto piloto y analizar su eficacia. Esta fase mostrará si tus modelos predictivos pueden identificar problemas reales, si tu equipo confía en las alertas y si los resultados hacen que merezca la pena ampliar la iniciativa.
Despliegue del proyecto piloto y validación de las alertas
Ahora que el trabajo de base está completo, es el momento de pasar a la supervisión activa y la respuesta. Comience instalando sensores en los activos seleccionados y confirmando que todas las conexiones funcionan correctamente. Procure que la proporción entre sensores y activos sea de 1,4:1. [4]. Garantice que las pasarelas se integran perfectamente en su red actual para mantener un flujo de datos ininterrumpido. [4].
Establezca un proceso claro para gestionar las alertas: Supervisión → Análisis de IA → Revisión humana → Alertas prescriptivas → Ejecución del trabajo a través de GMAO → Cierre. [6]. Este enfoque "humano" minimiza los falsos positivos y genera confianza en el equipo de mantenimiento.
Clasifique cada notificación en una de estas tres categorías: Reparación/Futura reparación, Observación, o Vigilar y esperar [4]. Por ejemplo, en una planta de producción de alimentos, un software predictivo detectó altos niveles de vibración en un rodamiento de una cinta transportadora, un problema que no era detectable ni por la vista ni por el oído. Al programar el mantenimiento durante un tiempo de inactividad previsto, el equipo evitó cinco horas de paradas imprevistas, ahorrando $50.000 a un coste de inactividad de $10.000 por hora. Esta única alerta validó el retorno de la inversión del piloto. [4].
Mantenga informadas a las partes interesadas con actualizaciones periódicas y breves comprobaciones. Esto ayuda a suavizar la transición a través del aumento inicial de la actividad de mantenimiento, a menudo conocido como el "valle de lo peor antes de lo mejor"." [3].
Supervisar los indicadores clave de rendimiento (KPI)
Una vez validadas las alertas, céntrese en el seguimiento de las mejoras cuantificables a través de KPI específicos. No espere al final del periodo de 90 días para evaluar los progresos. En su lugar, establezca puntos de control a los 30 y 60 días para comparar los resultados con sus objetivos iniciales. [4]. Utilice una combinación de métricas de fiabilidad, eficiencia operativa, ahorro de costes y consumo de energía para obtener una imagen completa del rendimiento.
| Categoría de KPI | Métrica | Ideas proporcionadas |
|---|---|---|
| Fiabilidad | Tiempo medio entre fallos (MTBF) | Comprueba si los activos funcionan durante más tiempo sin problemas |
| Capacidad de respuesta | Tiempo medio de reparación (MTTR) | Mide la rapidez con que se realizan las reparaciones |
| Productividad | Eficacia global de los equipos (OEE) | Evalúa si los activos producen más con menos tiempo de inactividad |
| Proactividad | Porcentaje de mantenimiento planificado (PMP) | Supervisa el paso del mantenimiento reactivo al planificado |
| Finanzas | Evitar costes de mantenimiento | Calcula el ahorro derivado de la prevención de fallos |
| Sostenibilidad | Energía por pieza | Realiza un seguimiento de la reducción del consumo de energía y de las emisiones de CO₂. |
El mantenimiento predictivo suele reducir los costes de explotación y mantenimiento entre 5% y 10%, mientras que las herramientas de fabricación inteligente pueden mejorar el tiempo de actividad de los equipos entre 10% y 20%. [12]. Para calcular el ahorro financiero, utilice la fórmula: (Horas de inactividad ahorradas) × (Coste por hora) [4].
Para una mayor eficacia, integre su plataforma predictiva con su sistema GMAO o ERP existente. Esto garantiza que las alertas generen automáticamente órdenes de trabajo y solicitudes de piezas de repuesto [12].
Perfeccionamiento basado en los resultados iniciales
Utilice los datos recopilados durante la prueba piloto para realizar ajustes. Cuando se sustituyan piezas, haga que los técnicos las inspeccionen para confirmar lo cerca que estuvieron de fallar. [1][2]. Este paso ayuda a verificar la exactitud de sus modelos o pone de relieve las áreas que necesitan mejoras.
Si un activo falla de forma inesperada, realice un análisis de la causa raíz para determinar qué ha fallado. [1][2]. ¿Se ha pasado por alto un modo de fallo concreto? ¿Eran demasiado altos los umbrales del algoritmo? Utilice estos resultados para afinar sus modelos ajustando las frecuencias de muestreo, añadiendo nuevos tipos de sensores o revisando los umbrales de acción. [1][2].
Por ejemplo, un taller alemán de chapa metálica reequipó 12 prensas con sensores habilitados para IA. En sólo tres meses, redujeron las paradas no planificadas en 25% al detectar fluctuaciones de par que los PLC estándar no detectaban. Esto también mejoró la precisión de la programación al reducir la variación del tiempo de ciclo en 15%. [13].
Mantenga el compromiso de su equipo de mantenimiento con sesiones periódicas de información. Asegúrese de que las alertas estén integradas en sus flujos de trabajo diarios, para que no se descarten como una fuente más de ruido. Un proyecto piloto bien ejecutado no sólo demuestra el valor del sistema, sino que también sienta las bases para el éxito a largo plazo.
Evaluar los resultados y planificar la ampliación
Analizar los éxitos y los retos del proyecto piloto
Una vez concluida la prueba piloto de 90 días, es hora de analizar qué ha funcionado y qué no. Empiece por comparar los resultados con los objetivos SMART que fijó al principio. No se trata sólo de confirmar que la tecnología funciona como se esperaba, sino de comprobar si realmente ahorra costes. [4].
Revise todas las alertas generadas por su sistema durante el piloto. Cuando los técnicos actúen sobre estas alertas y sustituyan piezas, examine esos componentes para ver lo cerca que estaban del fallo real. Esta validación práctica genera confianza en el sistema y pone de manifiesto dónde es necesario ajustar los umbrales del algoritmo. [1][2].
No se sorprenda si la actividad de mantenimiento se dispara al principio. Esto suele ocurrir porque el sistema descubre problemas que antes estaban ocultos. [3][1]. Es una buena señal: significa que los datos de referencia son cada vez más precisos. Documenta tanto tus éxitos, como los fallos evitados, como cualquier fallo, como averías inesperadas, para mejorar tus modelos antes de ampliarlos. [2][1]. Tenga en cuenta que los datos predictivos suelen necesitar entre 90 y 180 días para desarrollarse plenamente. [1]. Esta información le servirá de guía para planificar una aplicación más amplia.
Cuantificar la rentabilidad y el impacto empresarial
Para calcular el ROI, multiplique el número de horas de inactividad evitadas por el coste por hora de inactividad. Evalúe las mejoras en fiabilidad, ahorro de costes y eficacia operativa. Compare sus métricas previas al piloto -como el tiempo medio entre fallos (MTBF), la eficacia general de los equipos (OEE) y los gastos totales de mantenimiento- con los resultados de su prueba de 90 días. [1][2]. No olvide tener en cuenta los beneficios secundarios, como menos pedidos urgentes de piezas de repuesto, menos horas de inspección manual y un cambio del mantenimiento reactivo al planificado. [4][1][6]. Por ejemplo, la ciudad de Tulsa identificó un fallo crítico de un activo durante su prueba, y los ahorros de ese único incidente cubrieron dos años de costes de servicios de mantenimiento predictivo. [6].
Cuando presente el ROI a las partes interesadas, evite la jerga técnica. Utilice métricas claras, como porcentajes de reducción de los tiempos de inactividad imprevistos, ahorros en dólares por evitar costes de mantenimiento y mejoras en las tasas de finalización puntual del mantenimiento. [6]. Algunas organizaciones afirman que cada $1 invertido en mantenimiento predictivo genera $8 de ahorro, lo que constituye un argumento de peso para su ampliación. [6].
Con estos resultados en la mano, estará listo para pasar de un programa piloto a un enfoque de mantenimiento integral para toda la cartera.
Desarrollar una hoja de ruta a largo plazo con Oxand Simeo™

La ampliación a partir de un proyecto piloto exitoso requiere una hoja de ruta bien pensada que conecte las ganancias iniciales con los objetivos de gestión de activos a largo plazo. Oxand Simeo™ puede ayudarle a crear un plan estratégico basado en datos reales a partir del retorno de la inversión y la reducción del tiempo de inactividad demostrados en su proyecto piloto.
Oxand Simeo™ combina sus conocimientos sobre el piloto con más de 10.000 modelos de envejecimiento y 30.000 leyes de mantenimiento para simular el rendimiento de toda su cartera de activos a lo largo del tiempo. Esto le permite priorizar las inversiones, incluso para los activos que no formaban parte del piloto, mediante el uso de modelos probabilísticos para predecir dónde es probable que se produzcan fallos y sus costes potenciales.
Empiece por utilizar sus datos piloto para crear un marco de evaluación de la criticidad. A continuación, amplíe sistemáticamente su enfoque a los activos de alto riesgo y alto coste en primer lugar. [6]. A medida que sus datos crezcan, pase del análisis manual a herramientas automatizadas impulsadas por IA y aprendizaje automático, integradas con sus sistemas GMAO o ERP. [2][1][6].
Su hoja de ruta también debe abordar los cambios organizativos necesarios para el éxito. Como señala Terrence O'Hanlon, del Fundación para el Liderazgo en Fiabilidad lo pone:
"El mantenimiento 4.0 es una versión digital asistida por máquinas de todas las cosas que hemos estado haciendo durante los últimos cuarenta años como humanos para garantizar que nuestros activos aporten valor a nuestra organización" [3].
Aproveche los logros de su proyecto piloto para demostrar su valor, obtener el apoyo de las partes interesadas y crear un equipo multifuncional, que incluya directores de mantenimiento, ingenieros de fiabilidad, responsables de TI y supervisores de operaciones, para mantener el mantenimiento predictivo en toda su organización. [6].
Establezca hitos claros para su plan de ampliación y realice un seguimiento continuo de los avances: no espere otros 90 días para medir los resultados. Los resultados típicos incluyen una reducción de costes de 10-25% en actividades de mantenimiento específicas y mejoras notables en la disponibilidad de los activos y la eficiencia energética. Con una hoja de ruta que conecte el éxito de su proyecto piloto con la planificación de activos a largo plazo, estará bien posicionado para convertir los beneficios a corto plazo en mejoras operativas sostenibles.
Conclusión: De las ganancias rápidas al valor a largo plazo
Lecciones clave del proyecto piloto
El proyecto piloto de 90 días demostró claramente una cosa: el mantenimiento predictivo consiste en ahorrar dinero. [4]. Los equipos más pequeños y centrados tienden a obtener mejores resultados que los comités más grandes, y empezar con sólo 5% de sus activos -normalmente entre 15 y 50 unidades- proporciona datos suficientes para demostrar el valor sin abrumar a su organización. [4].
¿Otro punto clave? El aumento inicial de la actividad de mantenimiento no es un contratiempo. En realidad, el sistema está haciendo su trabajo y descubriendo problemas ocultos que ya existían. [1]. El éxito depende de la combinación de los conocimientos digitales con la experiencia sobre el terreno de sus técnicos. Esta combinación de tecnología y criterio humano es lo que convierte una prueba piloto en un programa sostenible.
El camino hacia una mejor gestión de activos
Las lecciones de su proyecto piloto van más allá del mantenimiento: ponen de relieve cómo el mantenimiento predictivo se vincula a objetivos organizativos más amplios. Al pasar de las reparaciones reactivas a la planificación proactiva, su objetivo es "un tiempo de inactividad casi nulo y un desperdicio casi nulo". Este cambio no sólo repercute en los costes, sino que mejora la rentabilidad, la seguridad y los resultados medioambientales. [5]. La mayor vida útil de los equipos, el menor número de reparaciones de emergencia y la racionalización de los inventarios de piezas de repuesto no sólo ahorran dinero, sino que también hacen que los lugares de trabajo sean más seguros y reducen el impacto medioambiental.
El marco de datos establecido durante el piloto -ya sea a través de Oxand Simeo™ u otro sistema- sienta las bases para una planificación más inteligente de la inversión en activos. Con modelos probabilísticos que predicen fallos potenciales y sus costes, puede priorizar las inversiones en toda su cartera en lugar de centrarse únicamente en los activos piloto. Este enfoque transforma el mantenimiento de un gasto necesario en una herramienta estratégica para gestionar los riesgos, mantener los niveles de servicio y cumplir los objetivos de descarbonización.
Comience su viaje hacia el mantenimiento predictivo
Con esta información en la mano, estará listo para ampliar su estrategia de mantenimiento predictivo. El marco de 90 días muestra que no necesita años de trabajo preliminar ni una red de sensores masiva para empezar. Lo que sí necesita son objetivos claros, activos piloto cuidadosamente seleccionados y el compromiso de evaluar objetivamente los resultados. Empezar poco a poco permite obtener resultados rápidos, generar confianza y presentar argumentos sólidos para ampliar el programa.
Oxand Simeo™ puede ayudarle a aprovechar esos éxitos piloto y ampliarlos a toda su cartera. Al integrar sus datos con su amplia biblioteca de más de 10.000 modelos de envejecimiento y 30.000 leyes de mantenimiento, proporciona un camino claro hacia adelante. Tanto si gestiona infraestructuras como edificios o carteras de activos mixtas, los siguientes pasos están claros: utilice el éxito de su proyecto piloto para conseguir el apoyo de las partes interesadas, cree un enfoque estandarizado y trace un plan a largo plazo que vincule el ahorro inmediato de costes con una gestión sostenible de los activos. Las ganancias rápidas de su proyecto piloto son sólo el principio de un viaje hacia el éxito mensurable a largo plazo.
Preguntas frecuentes
¿Cómo puedo conseguir que las partes interesadas se sumen a un proyecto piloto de mantenimiento predictivo?
Para ganarse el apoyo de las partes interesadas, empiece por presentar un un caso empresarial claro que vincule el proyecto piloto a resultados financieros cuantificables. Por ejemplo, establezca objetivos concretos, como reducir el tiempo de inactividad imprevisto en un porcentaje determinado o ahorrar en gastos de reparación, como evitar $450.000 en tiempo de inactividad en seis meses. Desarrolle un modelo de retorno de la inversión sencillo y establezca un calendario claro, como 30 días para la instalación, 60 días para la integración y 90 días para la optimización. De este modo, las partes interesadas sabrán exactamente cuándo esperar los resultados.
Asegúrese de que el proyecto piloto se ajusta a las prioridades de su organización e integre desde el principio a un equipo multifuncional para establecer la credibilidad. Asigne responsabilidades claras, programe actualizaciones periódicas y realice un seguimiento de los indicadores clave, como las horas de inactividad, los costes de mantenimiento por activo y la eficiencia de la mano de obra. Estos datos facilitarán la comprensión del valor del proyecto piloto y demostrarán el progreso de forma eficaz.
Por último, posicionar al piloto como oportunidad de bajo riesgo y alta recompensa con la posibilidad de ahorrar costes a largo plazo. Destaque cómo un proyecto piloto con éxito podría reducir el tiempo de inactividad en 45-65% y evitar costosas averías. Enmarcando el proyecto como un ensayo estratégico orientado a los resultados, ayudará a las partes interesadas a ver su valor a largo plazo y facilitará su compromiso.
¿Qué parámetros de rendimiento debo controlar durante un proyecto piloto de mantenimiento predictivo?
Durante un proyecto piloto de mantenimiento predictivo, es esencial vigilar las métricas de rendimiento adecuadas para medir su éxito y demostrar su valor. Empiece por hacer un seguimiento de reducción del tiempo de inactividad, que mide el porcentaje de tiempo ahorrado gracias a la prevención de averías en los equipos. A continuación, evalúe ahorro en costes de mantenimiento para ver cuánto dinero se ahorra gracias a procesos más eficientes. No olvide analizar eficacia general de los equipos (OEE) - una combinación de tiempo de actividad, velocidad de rendimiento y calidad que ofrece una visión holística del funcionamiento de sus equipos.
También es importante evaluar la ROI y mejoras en tiempo de actividad de los activos para comprender los beneficios financieros y operativos. En conjunto, estas métricas proporcionan una imagen clara de la eficacia del proyecto piloto y pueden respaldar la decisión de ampliar los esfuerzos de mantenimiento predictivo a todas sus operaciones.
¿Cómo puedo seleccionar los mejores activos para un proyecto piloto de mantenimiento predictivo de 90 días?
Para elegir los activos adecuados para un proyecto piloto de mantenimiento predictivo, céntrese en aquellos que puedan mostrar resultados rápidos y medibles. Empiece por establecer objetivos empresariales claros - ya sea reducir los tiempos de inactividad imprevistos, reducir los costes de mantenimiento o aumentar la seguridad. Estos objetivos le guiarán hacia los activos más relevantes.
Siguiente, evaluar la criticidad de cada activo. Piense en factores como la pérdida potencial de ingresos por el tiempo de inactividad (por ejemplo, $100.000 por hora), los riesgos de seguridad y lo esencial que es el activo para la producción. Dé prioridad a los activos con mayor impacto global. Además, asegúrese de que los activos elegidos ya tienen datos de estado disponibles o pueden equiparse fácilmente con sensores (como sensores de vibración, temperatura o análisis de aceite). Esto ayuda a reducir el tiempo y los costes de configuración.
Para que todo sea manejable, seleccione un pequeño grupo de De 3 a 5 activos de alto impacto que cubren distintos tipos de equipos. Antes de seguir adelante, valide sus opciones con las partes interesadas para alinear las expectativas y obtener su apoyo. Este método puede ayudar a su proyecto piloto a generar información práctica en tan solo 90 días.
Entradas de blog relacionadas
- El mantenimiento predictivo para la gestión de activos (infraestructuras y bienes inmuebles) es fundamental - utilice el sitio web el sitio web:https://theiam.org
- Cómo el mantenimiento predictivo (sin IoT ni tiempo real) aporta valor a los propietarios de infraestructuras y activos de edificios
- Mantenimiento predictivo y ROI
- Cómo calcular el ROI real del mantenimiento predictivo (e incorporarlo a su plan de inversión)