






Machine learning transformeert onderhoud door problemen te voorspellen voordat ze zich voordoen, kosten te besparen en de betrouwbaarheid van bedrijfsmiddelen te verbeteren. Dit is wat u moet weten:
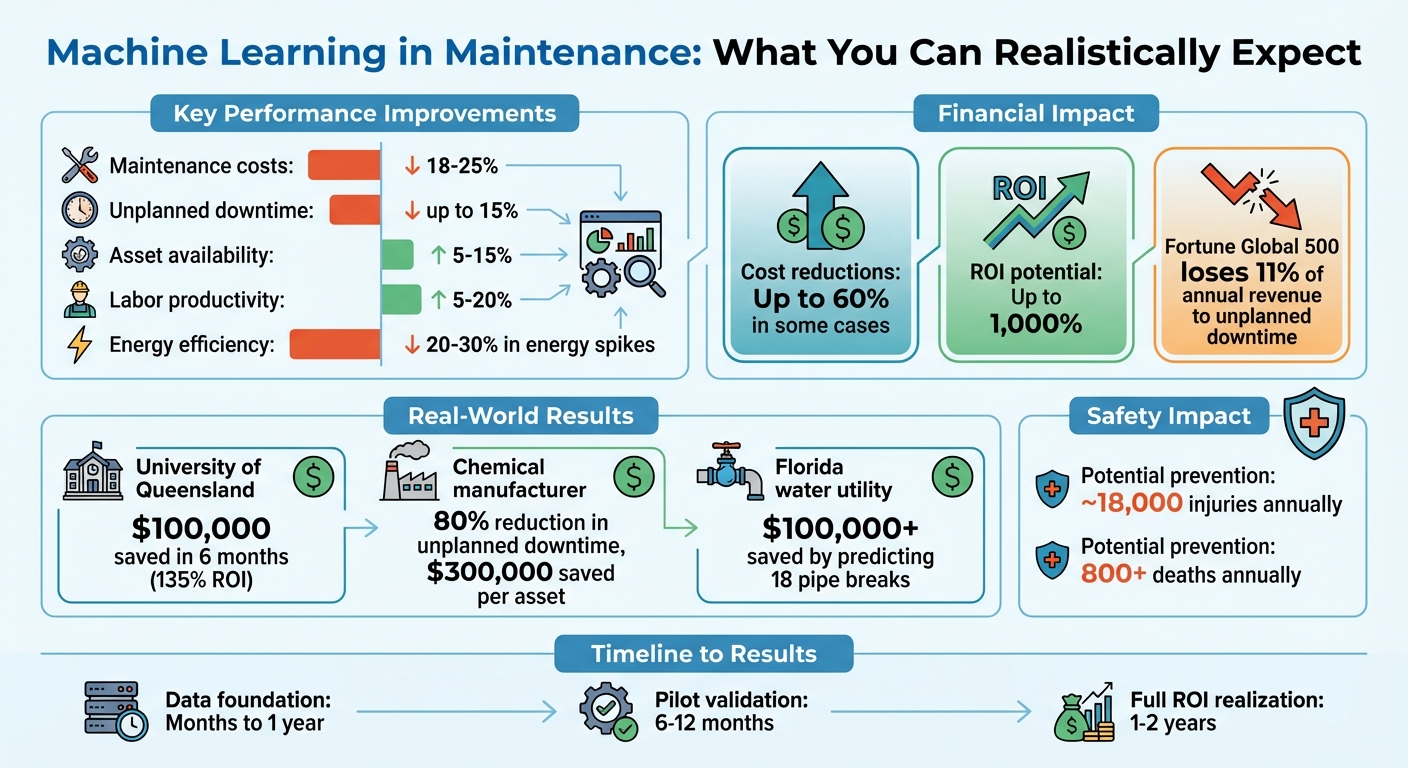
- Belangrijkste voordelen: Vermindert kosten van voorspellend vs reactief onderhoud met 18-25%, minimaliseert niet geplande stilstand tot 15%, verhoogt de beschikbaarheid van bedrijfsmiddelen met 5-15% en verbetert de arbeidsproductiviteit met 5-20%.
- Hoe het werkt: Gebruikt sensorgegevens en historische logbestanden om de gezondheid van apparatuur te analyseren en potentiële problemen vroegtijdig te signaleren.
- Resultaten uit de praktijk: Voorbeelden zijn de Universiteit van Queensland $100.000 besparen in zes maanden door voorspellend onderhoud te gebruiken op HVAC-systemen.
- Uitdagingen: Vereist gegevens van hoge kwaliteit, samenwerking tussen teams en het aanpakken van valse alarmen om vertrouwen in voorspellingen te garanderen.
Machine learning is geen snelle oplossing, maar als het doordacht wordt geïmplementeerd, kan het meetbare verbeteringen en besparingen op lange termijn opleveren.
Machine-leren in onderhoud: Belangrijkste voordelen en prestatiecijfers
Wat Machine Learning in Onderhoud daadwerkelijk kan opleveren
Belangrijkste voordelen en verbeteringen
Machine learning verandert onderhoud van een routinekost in een strategisch voordeel. Door storingspatronen in een vroeg stadium te detecteren, maakt het geplande reparaties mogelijk en helpt het de levensduur van bedrijfsmiddelen te verlengen door cascadestoringen te voorkomen. Het verbetert ook de energie-efficiëntie door verspillende handelingen te identificeren, waardoor energiepieken met 20-30% worden verminderd. Bovendien verbetert het de veiligheid op de werkplek door waarschuwingen voor hoge risico's te automatiseren, wat letsel bij technici kan verminderen en levens kan redden. Volgens schattingen kunnen deze verbeteringen jaarlijks ongeveer 18.000 verwondingen en meer dan 800 sterfgevallen voorkomen die verband houden met het onderhoud en de werking van machines. [2][8].
Deze voordelen zijn niet alleen theoretisch - ze vertalen zich in echte, meetbare prestatieverhogingen.
Typische prestatieverbeteringen en meetgegevens
Het implementeren van machine learning in onderhoud heeft indrukwekkende resultaten opgeleverd. De onderhoudskosten kunnen met 18-25% dalen, ongeplande stilstand kan tot 15% afnemen, de beschikbaarheid van bedrijfsmiddelen kan met 5-15% toenemen en de arbeidsproductiviteit kan met 5-20% verbeteren. In sommige gevallen lopen de kostenbesparingen op tot 60%. [1][6][7][8].
Zelfs kleine verbeteringen kunnen tot aanzienlijke besparingen leiden. De Fortune Global 500 verliest bijvoorbeeld ongeveer 11% van zijn jaarlijkse omzet aan niet geplande stilstand. [8]. Voorspellend onderhoud, aangedreven door machine learning, biedt naar schatting een rendement op investering (ROI) van wel 1.000% [1]. De werkelijke ROI hangt echter af van factoren zoals de kriticiteit van de bedrijfsmiddelen, de kosten van storingen en hoe goed de voorspellende inzichten worden geïntegreerd in de dagelijkse workflows.
De impact wordt nog duidelijker als we kijken naar voorbeelden uit de praktijk voor verschillende soorten activa.
Echte voorbeelden van verschillende soorten activa
Praktische toepassingen laten zien hoe machine learning zich aanpast aan specifieke behoeften van apparatuur. Neem de Universiteit van Queensland, die in maart 2016 een voorspellend onderhoudssysteem implementeerde om kritieke apparatuur te bewaken. [10]. Machine-learning algoritmen op maat voor activaspecifieke problemen hebben hun waarde bewezen: HVAC-systemen gebruiken deze hulpmiddelen om inefficiënties op te sporen, terwijl civiele constructies vertrouwen op rek- en temperatuurgegevens om onderhoudsvereisten te voorspellen. Deze systemen zorgen voor tijdige, nauwkeurige interventies, wat de tastbare waarde van machine learning in onderhoud aantoont.
sbb-itb-5be7949
Wat u nodig hebt voordat u begint
Gegevensvereisten en kwaliteitsnormen
Om effectieve modellen voor machinaal leren te bouwen, hebt u toegang nodig tot verschillende soorten gegevens, waaronder sensor- of telemetriegegevens (zoals trillings-, temperatuur- en drukmetingen), historische onderhoudslogboeken (met storingen, reparaties en bedrijfsuren uit het verleden) en contextuele gegevens (zoals gegevens over het bedrijfsmiddel, belastingsomstandigheden en externe factoren).
Het is van cruciaal belang dat uw sensorgegevens consistent zijn, vrij van ruis en opgenomen met gesynchroniseerde tijdstempels en gestandaardiseerde eenheden. Zonder de juiste context - zoals begrijpen of een temperatuurpiek het gevolg is van een storing of een geplande operationele verandering - kunnen uw ruwe gegevens leiden tot misleidende resultaten, zoals hoge fout-positieve percentages. Om dit te voorkomen, moet u ervoor zorgen dat uw gegevens uniforme standaarden volgen voor uw gehele activaportefeuille.
Een andere belangrijke overweging is het hebben van voldoende gelabelde storingsgebeurtenissen voor uw modellen om van te leren. Als dergelijke gebeurtenissen zeldzaam zijn, moet u misschien in plaats daarvan onopgemerkte anomaliedetectie onderzoeken. Controleer de dekking van uw sensoren aan de hand van bekende storingscondities - bijvoorbeeld met behulp van ISO 17359 als richtlijn - en streef naar ten minste 80% nauwkeurigheid, volledigheid en consistentie in uw gegevens voordat u verder gaat met pilots. [12]. Zodra uw gegevens aan deze kwaliteitsnormen voldoen, kunt u zich richten op het bouwen van het technische kader dat uw systeem zal ondersteunen.
Technische en organisatorische vereisten
Uw technische set-up moet componenten bevatten zoals edge gateways voor protocolvertaling, een verenigd hybride dataplatform en analysetools (bijv. Spark of Python). Deze systemen moeten in staat zijn om voorspellingen direct te integreren in uw Enterprise Asset Management (EAM) of Computerized Maintenance Management Systems (CMMS), zodat automatische werkorders gegenereerd kunnen worden.
Aan de organisatorische kant hangt succes af van de samenwerking tussen teams. Datawetenschappers moeten bijvoorbeeld nauw samenwerken met betrouwbaarheidsingenieurs en service-experts om modeluitvoer te valideren en de bruikbaarheid ervan te bevestigen. Het is ook van cruciaal belang om rollen en verantwoordelijkheden duidelijk af te bakenen - iemand moet de verantwoordelijkheid nemen voor AI-waarschuwingen en de acties die daarop volgen. Het management speelt hier een sleutelrol door datagestuurde besluitvorming zichtbaar te ondersteunen en nieuwe workflows aan te moedigen. Zoals McKinsey belangrijkste punten:
"Veranderingsbeheer waarbij de gebruiker centraal staat bij de implementatie is de meest kritische succesfactor om adoptie op grote schaal te garanderen"." [5].
Bovendien kunt u uw onderhoudsstrategie afstemmen op ISO 55001 Standaarden kunnen ervoor zorgen dat inspanningen op het gebied van machine learning bredere assetmanagementdoelstellingen en risicogebaseerde planning ondersteunen. Een goed ontworpen infrastructuur maakt niet alleen een soepele implementatie van uw modellen mogelijk, maar zorgt er ook voor dat voorspellingen naadloos in uw onderhoudsprocessen worden geïntegreerd. Als uw systemen er eenmaal zijn, is de volgende stap om te evalueren of u er klaar voor bent door middel van grondige gegevens- en organisatorische beoordelingen.
Hoe uw paraatheid evalueren
Begin met het doorlichten van uw gegevensinfrastructuur. Consolideer en standaardiseer informatie uit bronnen zoals CMMS, SCADA-systemen en zelfs spreadsheets. Houd in gedachten dat 60% van AI-succes afhangt van de gereedheid van uw gegevens [12]. Als uw datakwaliteit niet optimaal is, overweeg dan om een raamwerk voor datagovernance te implementeren. Tools zoals een gegevenscatalogus en het toewijzen van een duidelijk eigenaarschap voor gegevensbeheer kunnen een solide basis vormen.
Evalueer vervolgens het volwassenheidsniveau van uw organisatie. Bent u momenteel reactief (problemen oplossen nadat ze zich voordoen), preventief (een vast schema volgen) of toestandsafhankelijk (reageren op specifieke drempels)? Als u deze basislijn vaststelt, kunt u realistische doelen stellen en laten zien hoe machine learning uw bestaande onderhoudsstrategie kan verbeteren. Beslis of u moet investeren in het bijscholen van uw huidige team of in het inschakelen van externe experts om eventuele hiaten op te vullen.
Concentreer u bij het lanceren van een pilot op bedrijfsmiddelen die vaak storingen vertonen in plaats van op bedrijfsmiddelen die simpelweg het meest kritisch zijn. Deze aanpak geeft u meer gegevens om uw modellen te valideren. Een grote chemische fabrikant heeft bijvoorbeeld voorspellende analyses getest op zijn extruders, wat leidde tot een vermindering van niet geplande stilstand van 80% en een besparing van ongeveer $300.000 per bedrijfsmiddel. [13]. Het identificeren van bedrijfsmiddelen met hoge stilstandkosten en duidelijke storingspatronen in uw gegevens kan helpen om de ROI in een vroeg stadium aan te tonen, wat de weg vrijmaakt voor een bredere implementatie.
Hoe Machine Learning implementeren in Onderhoud
Implementatiefasen
Het introduceren van machine learning in onderhoud omvat een stap-voor-stap proces, dat begint met het bouwen van een solide basis voor uw gegevens. Dit betekent het standaardiseren van sensortags, het integreren van IT- en OT-systemen en het opslaan van tijdreeksgegevens op een betrouwbaar platform, zoals een bestuurd meerhuis of hybride systeem. [11]. Een goed georganiseerde gegevensbackbone legt de basis voor succesvolle pilots en soepele schaalvergroting.
De volgende stap is het uitvoeren van een proefprogramma met een specifieke categorie bedrijfsmiddelen. Richt u op apparatuur met duidelijke storingspatronen en een gedocumenteerde geschiedenis, in plaats van op uw meest kritieke bedrijfsmiddelen. Het U.S. Army Materiel Command testte bijvoorbeeld een "Predictive Asset Readiness" oplossing op geselecteerde wapensystemen. Met behulp van terugkerende neurale netwerken voorspelde het systeem de missiegereedheid en hielp het de planners om de onderhoudsschema's en voorraadniveaus nauwkeurig af te stemmen. [14]. Een pilot als deze valideert uw aanpak en wekt vertrouwen voordat u het op grotere schaal uitrolt.
Zodra de pilot slaagt, kunt u de oplossing uitbreiden naar uw hele portfolio met behulp van sjablonen voor activaklassen. Deze sjablonen fungeren als herbruikbare gidsen, waardoor het gemakkelijker wordt om nieuwe apparatuur te integreren zonder helemaal opnieuw te hoeven beginnen. [11]. Na de implementatie wordt voortdurend toezicht op het model een prioriteit om de nauwkeurigheid en betrouwbaarheid te handhaven.
Machine Learning-modellen beheren in de loop van de tijd
Modellen voor machinaal leren hebben voortdurende zorg nodig - ze zijn geen "set it and forget it" oplossing. Naarmate activa ouder worden en de omstandigheden veranderen, kunnen modellen aan nauwkeurigheid inboeten. Begin met het controleren op gegevensdrift, waaronder veranderingen in invoer-uitvoerrelaties, sensormetingen of kenmerkpatronen. [15]. Statistische tests zoals de Kolmogorov-Smirnov- of Chi-kwadraattest kunnen helpen om significante afwijkingen te vinden. [15].
Het juiste evenwicht vinden tussen precisie en terugroepen is cruciaal. Te veel valse alarmen kunnen technici frustreren en het vertrouwen ondermijnen. McKinsey benadrukt deze uitdaging:
"Een model dat veel alarmen genereert, vangt misschien alle storingen op (hoge recall), maar het is vaak onjuist en kan niet worden vertrouwd (lage precisie)" [5].
Om dit aan te pakken, brengt u datawetenschappers, betrouwbaarheidsingenieurs en buitendienstmonteurs samen om de modellen te verfijnen. Sluit de lus door ervoor te zorgen dat technici verslag uitbrengen over de werkresultaten en de resultaten van storingen. Deze terugkoppeling verbetert de nauwkeurigheid van het model na verloop van tijd en helpt bij het aanpakken van zeldzame storingen die optreden naarmate apparatuur ouder wordt. [5]. Voor scenario's met beperkte historische gegevens kunnen Generative Adversarial Networks (GANs) synthetische trainingsgegevens creëren om de gaten op te vullen. [4]. Betrouwbare modellen, ondersteund door gegevens uit de praktijk, kunnen dan direct invloed hebben op operationele beslissingen.
Voorspellingen koppelen aan onderhoudswerkzaamheden
De laatste stap is het integreren van deze voorspellingen in de dagelijkse onderhoudsworkflows. Integreer de modeluitvoer in uw CMMS- of EAM-systemen om automatisch werkorders te genereren. Neem sensorgegevens, aanbevolen acties en doorlooptijden op om processen te stroomlijnen en handmatige handelingen te elimineren. [11][14].
De Gezamenlijk programmabureau F-35 ontwikkelde de Artificial Intelligence Prognostic Steering Tool (AIPS) om reparaties aan zijn hele luchtvloot te beheren. Deze tool maakt gebruik van machine learning om onderhoudstaken te prioriteren, storingen te voorspellen en de prestaties van de toeleveringsketen te optimaliseren, om uiteindelijk de stilstandtijd te verminderen en de efficiëntie te verhogen. [14]. Uw implementatie moet een vergelijkbare aanpak volgen: zorg ervoor dat voorspellingen leiden tot specifieke acties in het veld, en stuur de geleerde lessen terug naar een gedeelde kennisbank.
Zoals Cloudera wijst erop:
"Als technici de waarschuwingen niet vertrouwen, zullen ze ze negeren. Integreer voorspellingen in vertrouwde workflows en meet de adoptie, niet alleen de precisie"." [11].
Zet "supergebruikers" in die de oplossing kunnen promoten en hun collega's kunnen helpen om zich aan de nieuwe processen aan te passen, om adoptie aan te moedigen [4]. Naast de dagelijkse werkzaamheden kunnen inzichten uit machinaal leren u helpen bij de kapitaal- en operationele planning voor de lange termijn. Gebruik voorspelde storingspatronen om meerjarige investeringsbeslissingen te sturen, voorraden te optimaliseren en budgetaanvragen te ondersteunen met solide gegevens. Deze aanpak verandert machine learning van een tactisch hulpmiddel in een strategisch hulpmiddel voor het beheren van uw gehele portfolio.
Beperkingen en wat u kunt verwachten
Technische en gegevensbeperkingen
Machine learning biedt mogelijkheden op het gebied van onderhoud, maar het voorspellen van storingen is niet eenvoudig omdat storingen zeldzaam zijn. Dit betekent dat datasets vaak scheefgetrokken zijn naar normale activiteiten, waardoor het moeilijk is om modellen te trainen die storingen betrouwbaar kunnen voorspellen. [16][1]. Chi-Guhn Lee, directeur van het Centre for Maintenance Optimization and Reliability Engineering, belicht deze kwestie:
"Een van de unieke problemen met onderhoudstoepassingen van machinaal leren is dat de datagrootte doorgaans kleiner is dan bij typische machinaal leren-toepassingen, omdat er relatief zelden storingen optreden." [16].
De uitdaging wordt nog groter door slechte gegevenskwaliteit. Onderhoudslogboeken worden vaak handmatig bijgehouden, wat kan leiden tot onvolledige of onnauwkeurige registraties van eerdere storingen. [4]. Zelfs als er sensorgegevens beschikbaar zijn, is dat niet altijd even eenvoudig. Identieke apparatuur, zoals pompen, kunnen verschillend presteren op basis van factoren zoals installatie of omgevingsomstandigheden, waardoor het moeilijk is om hetzelfde model toe te passen op alle bedrijfsmiddelen. [1].
Een ander probleem is het gebrek aan gedetailleerde gegevens. Veel datasets bevatten geen kritieke informatie zoals het type apparatuur, de fabrikant, de installatiedatum of de bedrijfsomstandigheden. [16]. Sensoren zelf kunnen defect raken, inconsistente metingen geven of helemaal afwezig zijn op oudere machines. Het bouwen van betrouwbare gegevenspijplijnen van randapparaten naar cloudsystemen blijft een technische hoofdpijn [3].
Maar de uitdagingen zijn niet puur technisch - organisatorische praktijken spelen ook een belangrijke rol in het succes van machine learning in onderhoud.
Organisatorische en procesuitdagingen
De echte obstakels zijn vaak mensen en processen, niet de technologie. Weerstand tegen verandering komt vaak voor bij de introductie van machine learning. Onderhoudsteams kunnen algoritmegestuurde aanbevelingen zien als een bedreiging voor hun expertise of baanzekerheid. Zonder duidelijke communicatie van de leiding over de voordelen kan de invoering stagneren. [7]. Deze menselijke factoren kunnen potentiële verbeteringen in efficiëntie en kostenbesparingen ondermijnen.
Bovendien hebben veel bedrijven te maken met tekorten aan vaardigheden. Het benodigde gespecialiseerde talent - zoals datawetenschappers, machine learning-ingenieurs en betrouwbaarheidsexperts - ontbreekt vaak. [5][13].
Een ander probleem is vals-positieve vermoeidheid. Als een model te veel onjuiste waarschuwingen genereert, kunnen technici zelfs geldige waarschuwingen gaan negeren. McKinsey legt uit:
"Een model dat veel alarmen genereert, vangt misschien alle storingen op (hoge recall), maar het is vaak onjuist en kan niet worden vertrouwd (lage precisie)" [5].
Verouderde apparatuur levert ook hindernissen op. Oudere machines moeten misschien achteraf met dure sensoren uitgerust worden om in een digitaal onderhoudssysteem opgenomen te kunnen worden. Zelfs als er voorspellingen worden gegenereerd, kan het lastig zijn om deze te integreren met bestaande CMMS- of EAM-systemen. Als deze voorspellingen niet naadloos worden omgezet in werkorders waarop actie kan worden ondernomen, dan dreigt het systeem meer een last dan een voordeel te worden.
Zodra de technische en organisatorische uitdagingen zijn aangepakt, is de volgende stap inzicht krijgen in de tijdlijn en het potentiële rendement.
ROI en tijdschema's
Voorspellend onderhoud heeft de potentie om de kosten met wel 60% te verlagen en de effectiviteit van apparatuur met meer dan 90% te verbeteren, maar deze voordelen hebben tijd nodig. [1]. Vroege modellen genereren vaak vals alarm, waardoor voortdurende verfijning nodig is om de nauwkeurigheid te verbeteren. [5]. Het kan maanden of zelfs een jaar duren voordat de modellen betrouwbaar werken.
De ROI-berekening moet ook rekening houden met fout-positieven. Een fout-positief percentage van 10% kan bijvoorbeeld leiden tot genoeg onnodig onderhoud om de besparingen door correct voorspelde storingen teniet te doen. [7]. Harold Brink, een partner bij McKinsey & Company, waarschuwt:
"Hoewel voorspellend onderhoud in de juiste omstandigheden aanzienlijke besparingen kan opleveren, worden deze besparingen in te veel gevallen tenietgedaan door de kosten van onvermijdelijke fout-positieven." [7].
Wanneer de ROI werkelijkheid wordt, komt deze uit meerdere gebieden: het vermijden van storingen, het uitstellen van kapitaaluitgaven, het verminderen van niet geplande stilstand (vaak met 20% tot 40%) en het verminderen van de totale eigendomskosten met ongeveer 10%. [4].
Zo heeft de Universiteit van Queensland in maart 2016 22 koelmachines uitgerust met IoT-sensoren. Binnen zes maanden bereikten ze een 135% rendement op investering, ongeveer $100.000 aan reparatiekosten besparen door storingen te voorkomen [9]. Evenzo, Voda AI hielp een waterbedrijf in Florida bij de beoordeling van meer dan 1.200 leidingen, waarbij 18 vermijdbare breuken met succes werden voorspeld en meer dan $100.000 aan reactieve onderhoudskosten werd bespaard [9].
Om de ROI te maximaliseren, is het van cruciaal belang om prioriteer waardevolle activa - met een robuuste sensordekking en een gedocumenteerde faalgeschiedenis. Deze leveren meestal het beste rendement op. Voor bedrijfsmiddelen met beperkte gegevens of onvoorspelbare storingspatronen bieden eenvoudigere methoden zoals conditiebewaking wellicht betere resultaten met minder complexiteit. [7]. Beginnen met proefprojecten om de waarde aan te tonen voordat er in de hele organisatie opgeschaald wordt, is vaak de beste aanpak. Door te focussen op kritieke bedrijfsmiddelen en voorspellende inzichten te integreren in de dagelijkse workflows, bent u verzekerd van succes op de lange termijn. [14][3].
Voorspellend onderhoud en meer: Hoe Machine Learning gebruiken zonder een datawetenschapper te zijn
Conclusie: Machine Learning laten werken voor uw onderhoudsstrategie
Machine learning heeft het potentieel om de onderhoudsresultaten aanzienlijk te verbeteren - ongeplande stilstand met 20-40% verminderen, de totale eigendomskosten met 10% verlagen en de onderhoudskosten met 18-25% verlagen. [4][6]. Maar het bereiken van deze resultaten is niet alleen een kwestie van het installeren van sensoren of het implementeren van algoritmen. Het vereist een doordachte, gefaseerde aanpak.
Begin met het prioriteren van bedrijfsmiddelen die de grootste impact hebben op activiteiten, veiligheid of productie wanneer ze defect raken. Richt u op apparatuur die al voldoende sensordekking heeft en een goed gedocumenteerde geschiedenis van storingen. Voordat u de inspanningen uitbreidt, het rendement op investering (ROI) valideren voor waardevolle activa. Deze methode bouwt niet alleen vertrouwen op binnen uw organisatie, maar levert ook concreet bewijs ter ondersteuning van verdere investeringen [3][14].
Zorg er vervolgens voor dat machine learning naadloos in uw operationele processen wordt geïntegreerd. Voorspellende waarschuwingen moeten direct worden gekoppeld aan werkbeheersystemen, zodat er onmiddellijk en actiegericht op onderhoud kan worden gereageerd. [5]. Samenwerking tussen datawetenschappers en onderhoudsmonteurs is essentieel om ervoor te zorgen dat aanbevelingen zowel praktisch zijn als afgestemd op de praktijk. [5][7]. Om vertrouwen te kweken en een soepele adoptie te garanderen, moet u technici er vroeg bij betrekken, duidelijke rolomschrijvingen geven en doorlopende trainingsmogelijkheden bieden. [4][5].
Om bij deze overgang te helpen, heeft de Oxand Simeo™ platform kan een waardevol hulpmiddel zijn. Met meer dan 10.000 eigen verouderingsmodellen en 30.000 onderhoudsrichtlijnen die in twee decennia zijn ontwikkeld, helpt dit modelgedreven platform organisaties om meerjarige CAPEX en OPEX te plannen binnen de beperkingen van budgetten, energie en CO2. Door over te stappen van reactief onderhoud naar Risicogebaseerde planning van activabeleggingen, Oxand Simeo™ levert 10-25% kostenbesparingen op bepaalde onderdelen, verlengt de levensduur van bedrijfsmiddelen en ondersteunt de naleving van ISO 55001-normen.
Met een duidelijke strategie, realistische doelen en een focus op bedrijfsmiddelen met een grote impact kan machine learning een revolutie teweegbrengen in de manier waarop u uw infrastructuur onderhoudt en erin investeert.
FAQs
Wat voor gegevens zijn er nodig om machine learning voor onderhoud te gebruiken?
Om machine learning effectief in onderhoud te implementeren, moet u nauwkeurige en betrouwbare gegevens is van cruciaal belang. Begin met hoogwaardige sensorgegevens die de fysieke toestand van bedrijfsmiddelen vastleggen, zoals trillingsniveaus, temperatuur (gemeten in °F) en druk. Deze gegevens moeten zo schoon mogelijk zijn - vrij van overmatige ruis of fouten - omdat onnauwkeurigheden de prestaties van uw modellen voor machinaal leren ernstig kunnen beïnvloeden.
Uw dataset moet ook breed en goed afgerond, met historische storingsgegevens, onderhoudslogboeken, operationele details (zoals laadvermogens of dienstroosters) en externe factoren zoals omgevingsfactoren. Consistentie is ook belangrijk. Gebruik gestandaardiseerde maateenheden (zoals imperiaal voor faciliteiten in de VS), zorg ervoor dat tijdstempels een uniform formaat volgen en neem duidelijke metadata op om de bronnen van uw gegevens te identificeren.
Daarnaast moet uw organisatie de infrastructuur hebben om grote hoeveelheden gegevens in real-time of bijna real-time verzamelen, opslaan en verwerken. Deze mogelijkheid is van vitaal belang voor modellen voor machinaal leren om nauwkeurige, tijdige voorspellingen te kunnen doen. Het opzetten van sterke praktijken voor gegevensbeheer zal helpen om de kwaliteit en beschikbaarheid van uw gegevens op de lange termijn te handhaven.
Hoe kunnen organisaties weerstand tegen het invoeren van machine learning in onderhoud aanpakken?
Om weerstand effectief aan te pakken, moet u eerst zorgen voor Sterke ondersteuning door leiderschap en een duidelijke business case presenteren. Benadruk meetbare resultaten, zoals jaarlijkse kostenbesparingen in dollars of uren van verminderde uitvaltijd. Een klein proefproject op een enkel systeem kan een revolutie teweegbrengen - door snelle voordelen te laten zien, zoals een 10% vermindering van ongeplande uitval, Dit kan een grote bijdrage leveren aan het opbouwen van vertrouwen binnen het team.
Het is net zo belangrijk om het onderhoudspersoneel er vroeg bij te betrekken. Moedig hun deelname aan taken zoals gegevensverzameling, labeling en hands-on training van gereedschap aan. Als werknemers zien dat hun expertise gewaardeerd wordt en begrijpen dat de technologie ontworpen is om hun werk te verbeteren - en niet om het te vervangen - dan neemt de bezorgdheid over de baanzekerheid vaak af.
Neem tot slot strategieën voor verandermanagement op in uw implementatie. Wijs teamkampioenen aan, stel duidelijke doelen (bijv, $50.000 aan besparingen op onderhoud tegen 31 december 2026), en vier de mijlpalen onderweg. Houd de communicatie open en consistent, en benadruk hoe machine learning de veiligheid kan verbeteren, de betrouwbaarheid van apparatuur kan vergroten en de efficiëntie kan stroomlijnen. Deze aanpak draagt bij aan een werkcultuur die innovatie en teamwerk omarmt.
Welke factoren beïnvloeden de ROI van het gebruik van machine learning voor voorspellend onderhoud?
Het rendement op investering (ROI) van een op machine-learning gebaseerd voorspellend onderhoudsprogramma hangt af van een aantal kritieke factoren. Eerst en vooral, hoogwaardige gegevens is een must. Betrouwbare voorspellingen zijn afhankelijk van gegevens die nauwkeurig, schoon en volledig zijn, omdat dit vals alarm helpt minimaliseren en ervoor zorgt dat het systeem effectief presteert. Net zo belangrijk is de prestaties van de voorspellende algoritmen. Hoe nauwkeuriger deze modellen zijn, hoe beter ze onverwachte storingen kunnen voorkomen, kosten voor reserveonderdelen kunnen verlagen en de behoefte aan noodreparaties kunnen verminderen.
Een ander belangrijk element is de naadloze integratie met bestaande onderhoudssystemen. Zonder dit worden waardevolle inzichten mogelijk niet omgezet in uitvoerbare stappen. De deskundigheid van het onderhoudsteam speelt ook een belangrijke rol. Vakkundig personeel is essentieel voor het interpreteren van de gegevens, het plannen van interventies en het afstemmen van de voorspellende modellen om blijvend succes te garanderen. Tot slot heeft het afstemmen van het programma op bredere bedrijfsdoelstellingen - zoals het minimaliseren van stilstand, het optimaliseren van arbeid en het verhogen van de beschikbaarheid van apparatuur - een directe invloed op de financiële resultaten.
Wanneer deze factoren effectief worden aangepakt, kunnen de besparingen aanzienlijk zijn. Veel organisaties rapporteren ROI-cijfers van 200% of meer. Bijvoorbeeld, het verminderen van niet geplande stilstand - wat duizenden dollars per minuut kan kosten - in combinatie met lagere onderhoudskosten en een hogere productiviteit, maakt de financiële voordelen van voorspellend onderhoud niet alleen meetbaar maar ook zeer impactvol.
Verwante Blog Berichten
- Voorspellend versus reactief onderhoud: gids voor kostenanalyse
- Voorspellend onderhoud voor activabeheer (infrastructuur en onroerend goed) is van cruciaal belang – raadpleeg de website: https://theiam.org
- Hoe voorspellend onderhoud (zonder IoT en realtime) waarde toevoegt voor eigenaren van infrastructuur en gebouwen
- Voorspellend onderhoud en ROI