






Il est possible de lancer un projet pilote de maintenance prédictive en 90 jours et d'obtenir des résultats immédiats. Voici le processus en bref :
- Pourquoi est-ce important ?La maintenance prédictive réduit les pannes d'équipement de 70%, diminue les coûts de maintenance de 25% et peut générer un retour sur investissement jusqu'à 8 fois supérieur. Les temps d'arrêt imprévus coûtent chaque année des milliards aux entreprises, ce qui rend cette transition essentielle pour gagner en efficacité et réaliser des économies.
- Défis: Les coûts initiaux élevés et le scepticisme des parties prenantes entravent souvent la mise en œuvre. Un projet pilote de 90 jours répond à ces préoccupations en démontrant rapidement sa valeur.
- Étapes pour commencer:
- Jours 1 à 30: Définissez des objectifs clairs (par exemple, réduire les temps d'arrêt ou les coûts), sélectionnez 15 à 50 actifs à fort impact et impliquez les parties prenantes.
- Jours 31 à 60: Construisez une base de données solide en créant un inventaire des actifs, en recueillant des données historiques et en établissant des références.
- Jours 61 à 90: Lancez le projet pilote, surveillez les résultats, validez les alertes et suivez les indicateurs clés de performance tels que le temps moyen entre pannes (MTBF) et les économies réalisées.
- Indicateurs clés: Concentrez-vous sur la fiabilité (MTBF), la réactivité (temps moyen de réparation), la productivité (efficacité globale des équipements) et l'impact financier (réduction des coûts de maintenance).
- RésultatsLes projets pilotes réussis permettent souvent de mettre au jour des problèmes cachés, d'éviter des échecs coûteux et de démontrer un retour sur investissement clair. Par exemple, le Ville de Tulsa économisé suffisamment lors d'un seul incident pour couvrir deux ans de frais de service.
Commencez modestement, prouvez la valeur ajoutée et créez une dynamique en vue d'améliorations à long terme. Ce guide garantit une approche structurée et mesurable de la maintenance prédictive.
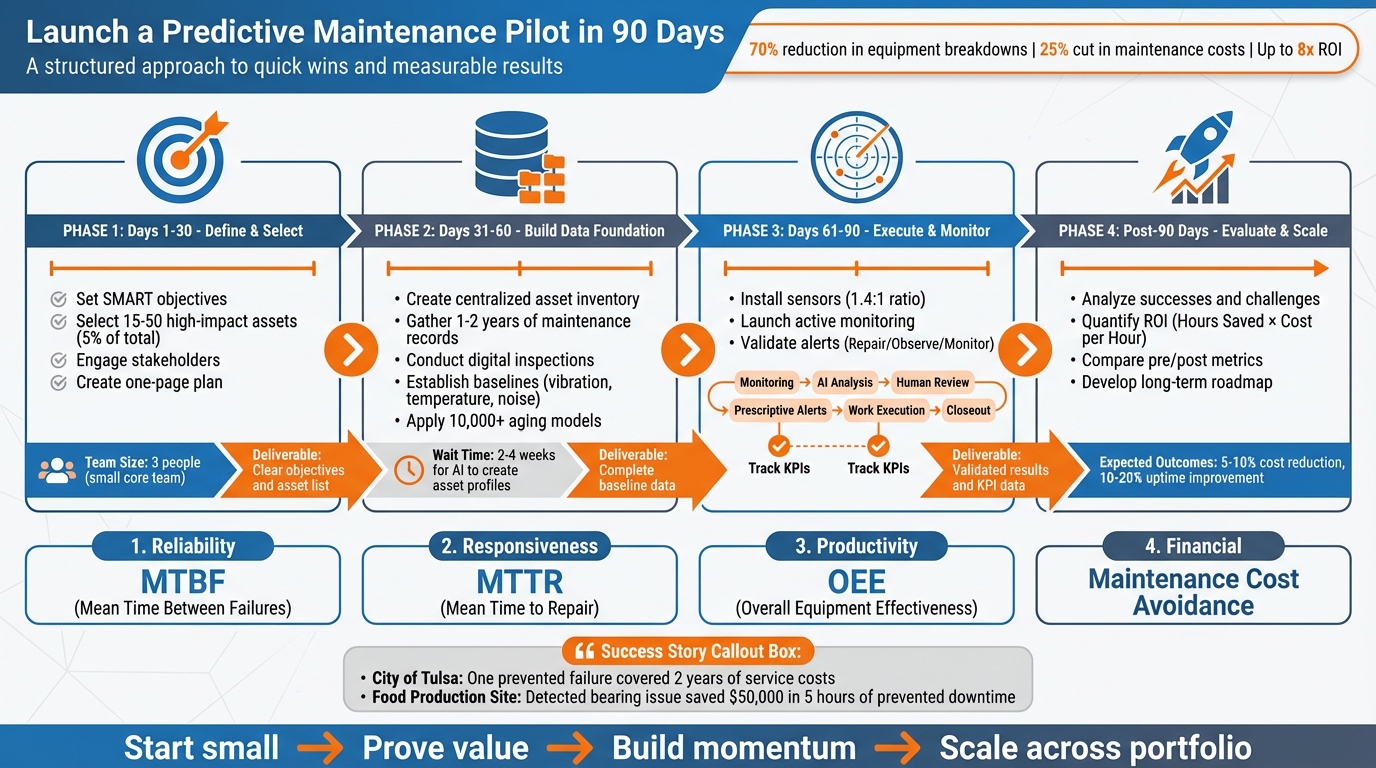
Calendrier de mise en œuvre du projet pilote de maintenance prédictive sur 90 jours
Qu'est-ce que la maintenance prédictive (PdM) ? Comment la mettre en œuvre ?
Jours 1 à 30 : définir les objectifs et sélectionner les actifs pilotes
Le premier mois est consacré à la préparation du terrain : définir vos ressources de test, établir des objectifs clairs et déterminer comment vous mesurerez le succès. Limitez votre équipe principale à environ trois personnes afin de garantir que les décisions soient prises rapidement et efficacement. L'objectif ? Un plan simple d'une page que tout le monde peut comprendre et soutenir.
Définir des objectifs SMART pour le projet pilote
Commencez par identifier la raison d'être de votre projet pilote. Cherchez-vous à réduire au minimum les appels d'urgence pendant les heures peu pratiques, à diminuer les coûts de maintenance pour un type d'actif spécifique ou à augmenter le temps de fonctionnement de la production ? Vos objectifs doivent répondre à des besoins commerciaux réels et ne pas se concentrer uniquement sur la technologie. Utilisez le cadre SMART pour définir vos objectifs :
- Spécifique: Cibler un actif ou un mode de défaillance particulier.
- Mesurable: Utilisez des indicateurs clés tels que le temps moyen avant panne (MTBF) ou les économies réalisées sur les coûts de maintenance.
- RéalisableCommencez par une approche de validation de la valeur afin de garantir la faisabilité.
- Pertinent: S'aligner sur les priorités commerciales générales.
- Limité dans le temps: Fixez un délai de 90 à 180 jours pour obtenir des informations exploitables.
Rédigez une phrase concise qui clarifie votre objectif :
" [Département] devrait [action] d'ici [délai], ce qui permettrait d'obtenir [résultat] tout en évitant [coût du problème]. "
Par exemple : " La maintenance devrait réduire les temps d'arrêt imprévus sur la machine CNC #7 de 15% en six mois, ce qui permettrait d'économiser $75 000 en pertes de production tout en évitant des réparations d'urgence coûteuses. " Cette clarté vous permet non seulement de mieux cibler vos efforts, mais aussi de simplifier la communication avec les parties prenantes qui approuvent les budgets ou allouent les ressources.
Une fois les objectifs clairement définis, l'étape suivante consiste à choisir les actifs qui démontreront le mieux la valeur de votre projet pilote.
Identifier les actifs pilotes à fort impact
Choisissez des actifs qui présentent des défaillances peu fréquentes mais coûteuses : ces " mauvais acteurs " épuisent souvent les ressources et peuvent même entraîner l'arrêt de la production. Par exemple, un site de production alimentaire a un jour surveillé les roulements de ses convoyeurs et détecté des niveaux de vibration anormalement élevés dans l'un d'entre eux. Bien que le défaut fût inaudible à l'oreille humaine, il a été détecté à temps, ce qui a permis de programmer les réparations lors de la maintenance régulière. Cette mesure proactive a évité cinq heures d'arrêt imprévu, soit une économie de $50 000 ($10 000 par heure). Cet événement unique a immédiatement justifié la valeur du projet pilote.
Sélectionnez entre 15 et 50 actifs, soit environ 51 TP3T du total des actifs de votre site, afin d'augmenter les chances de détecter au moins un incident dans les 90 jours. Concentrez-vous sur les actifs qui répondent aux critères suivants :
- Conservez au moins six mois de données historiques de maintenance dans votre système de GMAO afin de disposer de références fiables.
- Présentent une dégradation progressive (comme des changements au niveau des vibrations, de la chaleur ou du bruit) plutôt que des défaillances soudaines.
- Sont physiquement accessibles pour l'installation de capteurs et disposent d'une connectivité réseau fiable.
Impliquer les parties prenantes et définir les indicateurs de réussite
Une fois que vous avez défini vos objectifs et identifié les actifs, il est temps de recruter les bonnes personnes. Il est essentiel d'obtenir dès le début l'adhésion des principales parties prenantes. Les techniciens de maintenance peuvent identifier les actifs vulnérables et vérifier l'exactitude des alertes. Le personnel informatique assure un flux de données fluide entre les capteurs et votre système central. Les responsables de production alignent le projet pilote sur les résultats commerciaux, tels que l'amélioration du taux de rendement global (TRG).
Établissez des indicateurs clés de performance clairs et mesurables pour chaque groupe de parties prenantes. Par exemple :
- Techniciens: Se concentrer sur la réduction des appels d'urgence.
- directeurs financiers: Recherchez des dépenses de maintenance réduites et un retour sur investissement clair.
- Responsables de production: Priorité à la maximisation de la disponibilité des machines.
- Ingénieurs en fiabilité: Suivre les améliorations apportées au MTBF et à l'état général des actifs.
Avant de lancer le projet pilote, établissez une base de référence pour ces indicateurs. Cela vous permettra d'évaluer avec précision l'impact du projet pilote à la fin de la période de 90 jours.
Jours 31 à 60 : Construisez votre base de données
Maintenant que vos objectifs sont clairs et que les actifs pilotes ont été sélectionnés, il est temps de vous concentrer sur la création d'une base de données solide. Au cours des 30 prochains jours, vous établirez un inventaire précis des actifs, documenterez les conditions de référence et utiliserez des modèles prédictifs pour obtenir des informations exploitables pour votre programme pilote.
Configurez votre inventaire d'actifs avec Inventaire Simeo
Commencez par construire un registre centralisé des actifs servir de source de référence pour les informations relatives aux actifs. Ce registre doit inclure des détails tels que le nom, le type, l'emplacement, le fabricant/modèle, la date d'installation, le statut de la garantie, l'historique de maintenance, l'état d'évaluation et tout document technique important pour chaque actif. [10]. Organisez tout selon une hiérarchie claire : site, bâtiment, système et composant. Ainsi, lorsque les capteurs détectent un problème, vous pouvez rapidement identifier la partie spécifique qui nécessite votre attention. [9].
Ensuite, rassemblez les registres d'entretien des 1 à 2 dernières années à partir de votre système CMMS, EAM ou des carnets de bord des opérateurs. [9][5]. Ces données historiques fournissent un contexte permettant d'identifier les modes de défaillance courants et aident à établir une base de référence pour la comparaison. Pour votre projet pilote, concentrez-vous sur environ 51 TP3T de l'ensemble des actifs de votre site. Cela permet de garder les données gérables tout en augmentant les chances de détecter un événement de défaillance au cours des 90 premiers jours. [9].
Classez vos actifs sur une échelle de 1 à 5 en fonction de facteurs tels que la sécurité, l'impact sur la production, les coûts liés aux temps d'arrêt, la fréquence des pannes et les délais de réparation. [10]. Ce classement garantit que vos modèles prédictifs se concentrent sur les actifs qui ont le plus grand impact sur vos opérations.
Une fois votre inventaire établi, l'étape suivante consiste à documenter les conditions de référence.
Réaliser des inspections et des évaluations numériques
Utilisez des outils d'inspection numériques tels que Simeo GO établir les paramètres de fonctionnement de base tels que les niveaux de vibration, de température et de bruit [2][11]. Standardisez votre saisie de données grâce à des systèmes de notation cohérents, des codes d'erreur et des modèles numériques. [6].
" Sans données, impossible de faire des prévisions. Si vous ne disposez pas d'une base de référence sur le fonctionnement normal d'une pompe ou d'un convoyeur, vous ne pouvez pas identifier ni prévoir les anomalies. " – Bryan Sapot, PDG, SensrTrx [11]
Veillez à enregistrer à la fois les données numériques et les notes contextuelles, y compris les photos. Cette combinaison fournit une image complète pour une validation ultérieure. Par exemple, si un capteur de vibrations détecte une anomalie, les techniciens peuvent consulter les photos d'inspection récentes pour confirmer s'il y a une usure ou un désalignement visible. Vérifiez également dès le début que tous les outils numériques disposent d'une connexion réseau en direct afin d'éviter les lacunes dans les données qui pourraient perturber votre projet pilote. [4].
Une fois vos données de référence en place, vous êtes prêt à passer à la modélisation prédictive.
Appliquer des modèles prédictifs et des lois de maintenance
Il est maintenant temps de mettre à profit vos données d'inventaire propres et vos conditions de référence. Des plateformes telles que Oxand utiliser une bibliothèque de Plus de 10 000 modèles vieillissants et Plus de 30 000 lois relatives à l'entretien développés à partir de décennies d'expérience pratique. Ces modèles simulent la dégradation des actifs, estiment la durée de vie utile restante (RUL) et signalent les écarts par rapport aux performances normales. [7].
Commencez par une analyse des modes de défaillance et de leurs effets (FMEA) afin de hiérarchiser les modes de défaillance à haut risque. Cela implique de calculer un indice de priorité de risque (RPN) basé sur la gravité, la fréquence et la détectabilité. [7]. Ce faisant, vous vous assurez que vos algorithmes prédictifs se concentrent sur les risques les plus critiques pour la sécurité, la production ou les coûts.
Utilisation modèles de détection d'anomalies pour détecter les écarts par rapport aux références que vous avez établies. Il faut généralement deux à quatre semaines aux systèmes d'IA pour créer des profils d'exploitation uniques pour chaque actif. [4]. Pendant cette période, combinez les informations fournies par l'IA avec les commentaires de techniciens expérimentés afin d'éliminer les faux positifs et de confirmer que les alertes sont exploitables. [6]. Par exemple, un grand constructeur automobile a atteint une précision de 94% dans la prévision des pannes, évitant ainsi des temps d'arrêt imprévus et coûteux. [8].
sbb-itb-5be7949
Jours 61 à 90 : mise en œuvre du projet pilote et mesure des résultats
Une fois votre infrastructure de données prête, les 30 derniers jours seront consacrés au lancement de votre projet pilote et à l'analyse de son efficacité. Cette phase permettra de déterminer si vos modèles prédictifs sont capables d'identifier les problèmes réels, si votre équipe fait confiance aux alertes et si les résultats justifient la mise à l'échelle de l'initiative.
Déployer le projet pilote et valider les alertes
Maintenant que les bases sont posées, il est temps de passer à la surveillance active et à la réponse. Commencez par installer des capteurs sur les actifs sélectionnés et vérifiez que toutes les connexions fonctionnent correctement. Visez un ratio capteur/actif de 1,4:1. [4]. Assurez-vous que les passerelles s'intègrent parfaitement à votre réseau existant afin de maintenir un flux de données ininterrompu. [4].
Mettez en place un processus clair pour traiter les alertes : Surveillance → Analyse IA → Révision humaine → Alertes prescriptives → Exécution des travaux via CMMS → Clôture [6]. Cette approche " human-in-the-loop " minimise les faux positifs et renforce la confiance au sein de votre équipe de maintenance.
Classez chaque notification dans l'une des trois catégories suivantes : Réparation/Réparation future, Observation, ou Surveiller et attendre [4]. Par exemple, dans une usine agroalimentaire, un logiciel prédictif a signalé des niveaux de vibration élevés sur un roulement de convoyeur, un problème qui n'était pas détectable à l'œil nu ni à l'oreille. En programmant la maintenance pendant un arrêt planifié, l'équipe a évité cinq heures d'arrêt imprévu, économisant ainsi $50 000 euros, le coût de l'arrêt étant de $10 000 euros par heure. Cette seule alerte a validé le retour sur investissement du projet pilote. [4].
Tenez les parties prenantes informées grâce à des mises à jour régulières et de brefs points d'information. Cela permet de faciliter la transition pendant la période initiale d'activité intense liée à la maintenance, souvent appelée " la vallée du pire avant le mieux "." [3].
Surveiller les indicateurs clés de performance (KPI)
Une fois les alertes validées, concentrez-vous sur le suivi des améliorations mesurables à l'aide d'indicateurs clés de performance (KPI) spécifiques. N'attendez pas la fin de la période de 90 jours pour évaluer les progrès réalisés. Fixez plutôt des points de contrôle à 30 et 60 jours afin de comparer les résultats par rapport à vos objectifs initiaux. [4]. Utilisez un ensemble d'indicateurs portant sur la fiabilité, l'efficacité opérationnelle, les économies de coûts et la consommation d'énergie afin d'obtenir une vue d'ensemble des performances.
| Catégorie KPI | Métrique | Informations fournies |
|---|---|---|
| Fiabilité | Temps moyen entre pannes (MTBF) | Suivi de la durée de fonctionnement sans problème des actifs |
| Réactivité | Temps moyen de réparation (MTTR) | Mesure la rapidité avec laquelle les réparations sont effectuées. |
| Productivité | Taux de rendement global (TRG) | Évalue si les actifs produisent davantage avec moins de temps d'arrêt. |
| Proactivité | Pourcentage de maintenance planifiée (PMP) | Surveille le passage d'une maintenance réactive à une maintenance planifiée. |
| Financier | Éviter les coûts de maintenance | Calcule les économies réalisées grâce à la prévention des pannes |
| Durabilité | Énergie par pièce | Suivi des réductions de la consommation d'énergie et des émissions de CO₂ |
La maintenance prédictive réduit souvent les coûts d'exploitation et de maintenance de 51 % à 101 %, tandis que les outils de fabrication intelligents peuvent améliorer le temps de fonctionnement des équipements de 101 % à 201 %. [12]. Pour calculer les économies financières, utilisez la formule suivante : (Heures d'indisponibilité économisées) × (Coût par heure) [4].
Pour une meilleure efficacité, intégrez votre plateforme prédictive à votre système CMMS ou ERP existant. Cela garantit que les alertes génèrent automatiquement des ordres de travail et des demandes de pièces de rechange. [12].
Affiner en fonction des résultats initiaux
Utilisez les données recueillies pendant la phase pilote pour apporter des ajustements. Lorsque des pièces sont remplacées, demandez aux techniciens de les inspecter afin de confirmer dans quelle mesure elles étaient proches de la défaillance. [1][2]. Cette étape permet de vérifier la précision de vos modèles ou de mettre en évidence les domaines qui doivent être améliorés.
Si un actif tombe en panne de manière inattendue, effectuez une analyse des causes profondes afin d'identifier ce qui n'a pas fonctionné. [1][2]. Un mode de défaillance particulier a-t-il été négligé ? Les seuils de l'algorithme étaient-ils trop élevés ? Utilisez ces conclusions pour affiner vos modèles en ajustant les taux d'échantillonnage, en ajoutant de nouveaux types de capteurs ou en révisant les seuils d'action. [1][2].
Par exemple, un atelier allemand de tôlerie a modernisé 12 presses en les équipant de capteurs dotés d'une intelligence artificielle. En seulement trois mois, ils ont réduit les arrêts imprévus de 25% en détectant des fluctuations de couple que les automates programmables standard n'avaient pas détectées. Cela a également amélioré la précision de la planification en réduisant la variance des temps de cycle de 15%. [13].
Maintenez l'engagement de votre équipe de maintenance grâce à des sessions de feedback régulières. Veillez à ce que les alertes soient intégrées dans leurs flux de travail quotidiens, afin qu'elles ne soient pas considérées comme une simple source de bruit supplémentaire. Un projet pilote bien exécuté permet non seulement de prouver la valeur du système, mais aussi de jeter les bases d'un succès à long terme.
Évaluer les résultats et planifier la mise à l'échelle
Analyser les réussites et les défis du projet pilote
Maintenant que votre projet pilote de 90 jours est terminé, il est temps d'examiner de plus près ce qui a fonctionné et ce qui n'a pas fonctionné. Commencez par comparer vos résultats aux objectifs SMART que vous avez fixés au début. Il ne s'agit pas seulement de confirmer que la technologie fonctionne comme prévu, mais aussi de prouver qu'elle permet réellement de réaliser des économies. [4].
Passez en revue toutes les alertes générées par votre système pendant la phase pilote. Lorsque les techniciens ont donné suite à ces alertes et remplacé des pièces, examinez ces composants pour voir à quel point ils étaient proches d'une défaillance réelle. Cette validation pratique renforce la confiance dans le système et met en évidence les seuils algorithmiques qui pourraient nécessiter un ajustement. [1][2].
Ne soyez pas surpris si les activités de maintenance augmentent considérablement au début. Cela arrive souvent parce que le système révèle des problèmes qui étaient auparavant cachés. [3][1]. C'est un bon signe, cela signifie que vos données de référence deviennent plus précises. Documentez à la fois vos réussites, comme les défaillances évitées, et vos échecs, comme les pannes imprévues, afin d'améliorer vos modèles avant de passer à l'échelle supérieure. [2][1]. Gardez à l'esprit que les prévisions pertinentes nécessitent généralement entre 90 et 180 jours de données pour être pleinement développées. [1]. Ces informations vous guideront dans vos prochaines étapes lorsque vous planifierez une mise en œuvre à plus grande échelle.
Quantifier le retour sur investissement et l'impact commercial
Pour calculer le retour sur investissement, multipliez le nombre d'heures d'indisponibilité évitées par le coût horaire de l'indisponibilité. Évaluez les améliorations en termes de fiabilité, d'économies et d'efficacité opérationnelle. Comparez vos indicateurs pré-pilote, tels que le temps moyen entre pannes (MTBF), le taux de rendement global (OEE) et les dépenses totales de maintenance, avec les résultats de votre essai de 90 jours. [1][2]. N'oubliez pas de tenir compte des avantages secondaires, tels que la diminution des commandes de pièces de rechange d'urgence, la réduction des heures d'inspection manuelle et le passage d'une maintenance réactive à une maintenance planifiée. [4][1][6]. Par exemple, la ville de Tulsa a identifié une défaillance critique d'un équipement pendant son essai, et les économies réalisées grâce à cet incident unique ont couvert deux ans de coûts de service de maintenance prédictive. [6].
Lorsque vous présentez le retour sur investissement aux parties prenantes, évitez le jargon technique. Utilisez des indicateurs clairs tels que le pourcentage de réduction des temps d'arrêt imprévus, les économies réalisées grâce à la suppression des coûts de maintenance et l'amélioration des taux d'achèvement des opérations de maintenance dans les délais impartis. [6]. Certaines organisations indiquent que chaque $1 dépensé dans la maintenance prédictive génère $8 d'économies, ce qui constitue un argument convaincant en faveur d'une mise à l'échelle. [6].
Avec ces résultats en main, vous êtes prêt à passer d'un programme pilote à une approche de maintenance complète à l'échelle du portefeuille.
Élaborez une feuille de route à long terme avec Oxand Simeo™

Pour passer d'un projet pilote réussi à une mise en œuvre à plus grande échelle, il faut disposer d'une feuille de route bien pensée qui relie les premiers succès aux objectifs à long terme en matière de gestion des actifs. En s'appuyant sur le retour sur investissement et la réduction des temps d'arrêt démontrés dans votre projet pilote, Oxand Simeo™ peut vous aider à élaborer un plan stratégique basé sur des données réelles.
Oxand Simeo™ combine vos connaissances pilotes avec plus de 10 000 modèles de vieillissement et 30 000 lois de maintenance pour simuler les performances de l'ensemble de votre portefeuille d'actifs au fil du temps. Cela vous permet de hiérarchiser les investissements, même pour les actifs qui ne faisaient pas partie du projet pilote, en utilisant une modélisation probabiliste pour prédire où les défaillances sont susceptibles de se produire et leurs coûts potentiels.
Commencez par utiliser vos données pilotes pour créer un cadre d'évaluation de la criticité. Ensuite, élargissez systématiquement votre champ d'action en vous concentrant d'abord sur les actifs à haut risque et à coût élevé. [6]. À mesure que vos données augmentent, passez de l'analyse manuelle à des outils automatisés basés sur l'IA et l'apprentissage automatique, intégrés à vos systèmes CMMS ou ERP. [2][1][6].
Votre feuille de route doit également aborder les changements organisationnels nécessaires à la réussite. Comme l'explique Terrence O'Hanlon de la Fondation pour le leadership en matière de fiabilité le dit :
" La maintenance 4.0 est une version numérique assistée par des machines de tout ce que nous avons fait au cours des quarante dernières années en tant qu'êtres humains pour garantir que nos actifs apportent de la valeur à notre organisation. " [3].
Tirez parti des résultats obtenus par votre pilote pour démontrer la valeur ajoutée, obtenir le soutien des parties prenantes et constituer une équipe interfonctionnelle – comprenant des responsables de la maintenance, des ingénieurs en fiabilité, des responsables informatiques et des superviseurs des opérations – afin de pérenniser la maintenance prédictive dans l'ensemble de votre organisation. [6].
Définissez des étapes claires pour votre plan de mise à l'échelle et suivez les progrès en continu – n'attendez pas 90 jours supplémentaires pour mesurer les résultats. Les résultats typiques comprennent une réduction des coûts de 10 à 251 TP3T sur les activités de maintenance ciblées et des améliorations notables en termes de disponibilité des actifs et d'efficacité énergétique. Grâce à une feuille de route qui relie le succès de votre projet pilote à la planification à long terme des actifs, vous êtes bien placé pour transformer les gains à court terme en améliorations opérationnelles durables.
Conclusion : des gains rapides à la valeur à long terme
Principaux enseignements tirés du projet pilote
Le projet pilote de 90 jours a clairement démontré une chose : la maintenance prédictive permet avant tout de réaliser des économies. [4]. Les équipes plus petites et plus ciblées ont tendance à obtenir de meilleurs résultats que les comités plus importants, et commencer avec seulement 5% de vos actifs (généralement entre 15 et 50 unités) fournit suffisamment de données pour démontrer la valeur sans submerger votre organisation. [4].
Autre point important à retenir ? L'augmentation initiale des activités de maintenance n'est pas un revers. Il s'agit en fait du système qui fait son travail, en mettant au jour des problèmes cachés qui existaient déjà. [1]. Pour réussir, il faut combiner les connaissances numériques et l'expertise terrain de vos techniciens. C'est cette combinaison entre technologie et jugement humain qui transforme un projet pilote en programme durable.
La voie vers une meilleure gestion des actifs
Les enseignements tirés de votre projet pilote vont au-delà de la maintenance : ils soulignent comment la maintenance prédictive s'inscrit dans les objectifs plus larges de l'organisation. En passant d'une approche réactive à une planification proactive, vous visez " un temps d'arrêt et un gaspillage quasi nuls ". Ce changement a un impact qui va au-delà des coûts : il améliore la rentabilité, la sécurité et les résultats environnementaux. [5]. Une durée de vie prolongée des équipements, moins de réparations d'urgence et une rationalisation des stocks de pièces de rechange permettent non seulement de réaliser des économies, mais aussi de rendre les lieux de travail plus sûrs et de réduire l'impact environnemental.
Le cadre de données établi pendant la phase pilote, que ce soit via Oxand Simeo™ ou un autre système, jette les bases d'une planification plus intelligente des investissements dans les actifs. Grâce à des modèles probabilistes prédisant les pannes potentielles et leurs coûts, vous pouvez hiérarchiser les investissements dans l'ensemble de votre portefeuille au lieu de vous concentrer uniquement sur les actifs pilotes. Cette approche transforme la maintenance d'une dépense nécessaire en un outil stratégique pour gérer les risques, maintenir les niveaux de service et atteindre les objectifs de décarbonisation.
Commencez votre parcours vers la maintenance prédictive
Fort de ces informations, vous êtes prêt à déployer votre stratégie de maintenance prédictive à plus grande échelle. Le cadre de 90 jours montre qu'il n'est pas nécessaire de disposer de plusieurs années de travail préparatoire ou d'un réseau de capteurs gigantesque pour se lancer. Ce dont vous avez besoin, ce sont des objectifs clairs, des actifs pilotes soigneusement sélectionnés et la volonté d'évaluer objectivement les résultats. En commençant modestement, vous obtiendrez des résultats rapides, gagnerez en confiance et disposerez d'arguments solides pour étendre le programme.
Oxand Simeo™ peut vous aider à exploiter ces succès pilotes et à les étendre à l'ensemble de votre portefeuille. En intégrant vos données à sa vaste bibliothèque de plus de 10 000 modèles de vieillissement et 30 000 lois de maintenance, il vous offre une voie claire à suivre. Que vous gériez des infrastructures, des bâtiments ou des portefeuilles d'actifs mixtes, les prochaines étapes sont claires : utilisez le succès de votre projet pilote pour rallier le soutien des parties prenantes, créer une approche standardisée et élaborer un plan à long terme qui relie les économies immédiates à une gestion durable des actifs. Les gains rapides obtenus grâce à votre projet pilote ne sont que le début d'un parcours vers un succès mesurable et durable.
FAQ
Comment puis-je convaincre les parties prenantes de participer à un projet pilote de maintenance prédictive ?
Pour obtenir le soutien des parties prenantes, commencez par présenter un analyse de rentabilité claire qui lie le projet pilote à des résultats financiers mesurables. Par exemple, fixez des objectifs spécifiques tels que la réduction des temps d'arrêt imprévus d'un certain pourcentage ou la réduction des frais de réparation, par exemple en évitant $450 000 en temps d'arrêt sur six mois. Élaborez un modèle de retour sur investissement simple et établissez un calendrier clair, par exemple 30 jours pour la mise en place, 60 jours pour l'intégration et 90 jours pour l'optimisation. De cette façon, les parties prenantes sauront exactement quand elles peuvent espérer des résultats.
Assurez-vous que le projet pilote correspond aux priorités de votre organisation et faites appel dès le départ à une équipe pluridisciplinaire afin d'établir sa crédibilité. Attribuez des responsabilités claires, prévoyez des mises à jour régulières et suivez les indicateurs clés tels que les heures d'indisponibilité, les coûts de maintenance par actif et l'efficacité de la main-d'œuvre. Ces données permettront de comprendre facilement la valeur du projet pilote et de démontrer efficacement ses progrès.
Enfin, positionnez le pilote comme un opportunité à faible risque et à haut rendement avec un potentiel d'économies à long terme. Insistez sur le fait qu'un projet pilote réussi pourrait réduire les temps d'arrêt de 45 à 65 % et éviter des pannes coûteuses. En présentant le projet comme un essai stratégique axé sur les résultats, vous aiderez les parties prenantes à en percevoir la valeur à long terme et faciliterez leur engagement.
Quels indicateurs de performance dois-je surveiller pendant un projet pilote de maintenance prédictive ?
Au cours d'un projet pilote de maintenance prédictive, il est essentiel de surveiller les bons indicateurs de performance afin d'évaluer son succès et de prouver sa valeur. Commencez par suivre réduction des temps d'arrêt, qui mesure le pourcentage de temps gagné en prévenant les pannes d'équipement. Ensuite, évaluez économies sur les coûts de maintenance pour voir combien d'argent est économisé grâce à des processus plus efficaces. N'oubliez pas d'analyser efficacité globale des équipements (OEE) – une combinaison de disponibilité, de vitesse de performance et de qualité qui donne une vue d'ensemble du bon fonctionnement de votre équipement.
Il est également important d'évaluer le retour sur investissement et améliorations dans temps de disponibilité des actifs pour comprendre les avantages financiers et opérationnels. Ensemble, ces indicateurs fournissent une image claire de l'efficacité du projet pilote et peuvent étayer la décision d'étendre les efforts de maintenance prédictive à l'ensemble de vos opérations.
Comment sélectionner les meilleurs actifs pour un projet pilote de maintenance prédictive sur 90 jours ?
Pour choisir les bons actifs pour un projet pilote de maintenance prédictive, concentrez-vous sur ceux qui peuvent donner des résultats rapides et mesurables. Commencez par fixer des objectifs commerciaux clairs – qu'il s'agisse de réduire les temps d'arrêt imprévus, de diminuer les coûts de maintenance ou d'améliorer la sécurité. Ces objectifs vous guideront vers les actifs les plus pertinents.
Ensuite, évaluer la criticité de chaque actif. Pensez à des facteurs tels que la perte potentielle de revenus due aux temps d'arrêt (par exemple, $100 000 par heure), les risques pour la sécurité et l'importance de l'actif pour la production. Donnez la priorité aux actifs ayant le plus grand impact global. Assurez-vous également que les actifs que vous choisissez disposent déjà données de condition disponibles ou peut être facilement équipé de capteurs (tels que des capteurs de vibration, de température ou d'analyse d'huile). Cela permet de réduire le temps et les coûts d'installation.
Pour que les choses restent gérables, sélectionnez un petit groupe de 3 à 5 actifs à fort impact qui couvrent différents types d'équipements. Avant d'aller plus loin, validez vos choix auprès des parties prenantes afin d'harmoniser les attentes et d'obtenir leur soutien. Cette méthode peut aider votre projet pilote à générer des informations exploitables en seulement 90 jours.
Articles de blog connexes
- La maintenance prédictive pour la gestion des actifs (infrastructures et immobilier) est essentielle – consultez le site Web :https://theiam.org
- Comment la maintenance prédictive (sans IoT ni temps réel) apporte de la valeur aux propriétaires d'infrastructures et d'actifs immobiliers
- Maintenance prédictive et retour sur investissement
- Comment calculer le retour sur investissement réel de la maintenance prédictive (et l'intégrer à votre plan d'investissement)