






L'apprendimento automatico sta trasformando la manutenzione prevedendo i problemi prima che si verifichino, riducendo i costi e migliorando l'affidabilità delle risorse. Ecco cosa c'è da sapere:
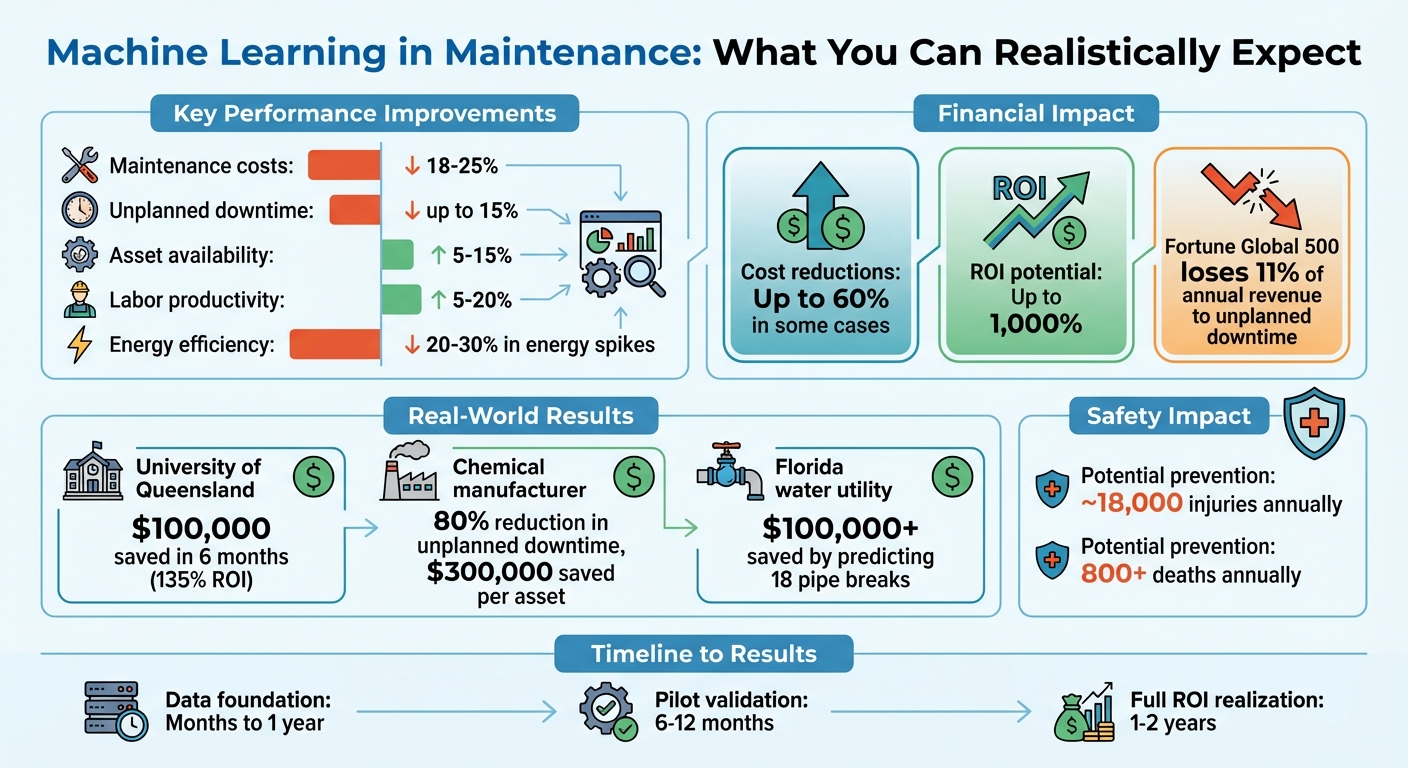
- Vantaggi principali: Riduce Costi di manutenzione predittivi e reattivi di 18-25%, riduce i tempi di inattività non programmati fino a 15%, aumenta la disponibilità delle risorse di 5-15% e migliora la produttività del lavoro di 5-20%.
- Come funziona: Utilizza i dati dei sensori e i registri storici per analizzare lo stato di salute delle apparecchiature, segnalando tempestivamente potenziali problemi.
- Risultati nel mondo reale: Gli esempi includono il Università del Queensland risparmiando $100.000 in sei mesi grazie alla manutenzione predittiva dei sistemi HVAC.
- Sfide: Richiede dati di alta qualità, collaborazione tra i team e la gestione dei falsi allarmi per garantire la fiducia nelle previsioni.
L'apprendimento automatico non è una soluzione rapida ma, se implementato in modo ponderato, può garantire miglioramenti misurabili e risparmi a lungo termine.
L'apprendimento automatico nella manutenzione: Benefici chiave e metriche delle prestazioni
Che cosa può offrire effettivamente l'apprendimento automatico nella manutenzione
Principali vantaggi e miglioramenti
L'apprendimento automatico trasforma la manutenzione da spesa di routine a vantaggio strategico. Individuando precocemente i modelli di guasto, consente di programmare le riparazioni e contribuisce a prolungare la durata di vita delle risorse evitando guasti a cascata. Inoltre, migliora l'efficienza energetica identificando le operazioni che sprecano risorse, riducendo i picchi di energia del 20-30%. Inoltre, migliora la sicurezza sul posto di lavoro automatizzando gli avvisi di rischio, che possono ridurre gli infortuni dei tecnici e salvare vite umane. Secondo le stime, questi progressi potrebbero potenzialmente prevenire circa 18.000 infortuni e oltre 800 decessi all'anno legati alla manutenzione e alle operazioni dei macchinari. [2][8].
Questi vantaggi non sono solo teorici, ma si traducono in un aumento delle prestazioni reale e misurabile.
Miglioramenti delle prestazioni e metriche tipiche
L'implementazione dell'apprendimento automatico nella manutenzione ha dato risultati impressionanti. I costi di manutenzione possono diminuire di 18-25%, i tempi di inattività non pianificati possono diminuire fino a 15%, la disponibilità degli asset può aumentare di 5-15% e la produttività del lavoro può migliorare di 5-20%. In alcuni casi, la riduzione dei costi ha raggiunto le 60%. [1][6][7][8].
Anche piccoli miglioramenti possono portare a risparmi significativi. Ad esempio, la Fortune Global 500 perde circa 11% del suo fatturato annuale a causa di fermi macchina non programmati. [8]. Si stima che la manutenzione predittiva, alimentata dall'apprendimento automatico, offra un ritorno sull'investimento (ROI) fino a 1.000% [1]. Tuttavia, il ROI effettivo dipende da fattori quali la criticità degli asset, il costo dei guasti e la capacità di integrare le informazioni predittive nei flussi di lavoro quotidiani.
L'impatto diventa ancora più chiaro se si considerano gli esempi reali relativi a diversi tipi di attività.
Esempi reali di diverse tipologie di asset
Le applicazioni pratiche evidenziano come l'apprendimento automatico si adatti alle esigenze specifiche degli asset. Prendiamo ad esempio l'Università del Queensland, che nel marzo 2016 ha implementato un sistema di manutenzione predittiva per monitorare le apparecchiature critiche [10]. Gli algoritmi di apprendimento automatico adattati a problemi specifici degli asset hanno dimostrato la loro validità: I sistemi HVAC utilizzano questi strumenti per rilevare le inefficienze, mentre le strutture civili si basano sui dati di deformazione e temperatura per prevedere i requisiti di manutenzione. Questi sistemi garantiscono interventi tempestivi e precisi, dimostrando il valore tangibile del machine learning nella manutenzione.
sbb-itb-5be7949
Cosa serve prima di iniziare
Requisiti dei dati e standard di qualità
Per costruire modelli di apprendimento automatico efficaci, è necessario accedere a diversi tipi di dati, tra cui i dati dei sensori o della telemetria (come le letture di vibrazioni, temperatura e pressione), i registri di manutenzione storici (che coprono guasti, riparazioni e ore di funzionamento passate) e i dati contestuali (come i dettagli dell'asset, le condizioni di carico e i fattori esterni).
È fondamentale che i dati dei sensori siano coerenti, privi di disturbi e registrati con timestamp sincronizzati e unità standardizzate. Senza il giusto contesto, come ad esempio capire se un picco di temperatura è il risultato di un guasto o di una modifica operativa pianificata, i dati grezzi potrebbero portare a risultati fuorvianti, come ad esempio un alto tasso di falsi positivi. Per evitare ciò, assicuratevi che i dati seguano standard uniformi per l'intero portafoglio di asset.
Un'altra considerazione fondamentale è la presenza di un numero sufficiente di eventi di guasto etichettati da cui i modelli possano apprendere. Se tali eventi sono rari, potrebbe essere necessario esplorare il rilevamento delle anomalie non supervisionato. Verificate la copertura dei vostri sensori rispetto alle modalità di guasto conosciute, ad esempio usando ISO 17359 come linea guida e puntare ad almeno 80% accuratezza, completezza e coerenza dei dati prima di procedere con i piloti. [12]. Una volta che i dati soddisfano questi standard di qualità, ci si può concentrare sulla costruzione del quadro tecnico che supporterà il sistema.
Requisiti tecnici e organizzativi
La configurazione tecnica dovrebbe includere componenti come gateway edge per la traduzione dei protocolli, una piattaforma dati ibrida unificata e strumenti di analisi (ad esempio, Spark o Python). Questi sistemi dovrebbero essere in grado di integrare le previsioni direttamente nell'Enterprise Asset Management (EAM) o nei sistemi di gestione della manutenzione computerizzata (CMMS), consentendo la generazione automatica di ordini di lavoro.
Dal punto di vista organizzativo, il successo dipende dalla collaborazione tra i team. Ad esempio, i data scientist devono lavorare a stretto contatto con gli ingegneri dell'affidabilità e gli esperti di assistenza per convalidare i risultati dei modelli e confermarne la praticità. Anche la chiara definizione di ruoli e responsabilità è fondamentale: qualcuno deve assumersi la responsabilità degli avvisi generati dall'IA e delle azioni che ne conseguono. Il management svolge un ruolo chiave in questo senso, sostenendo visibilmente il processo decisionale basato sui dati e incoraggiando nuovi flussi di lavoro. Come McKinsey punti salienti:
"La gestione del cambiamento che pone l'utente al centro dell'implementazione è il fattore di successo più critico per garantire l'adozione su scala"." [5].
Inoltre, l'allineamento della strategia di manutenzione con ISO 55001 Gli standard possono contribuire a garantire che gli sforzi di apprendimento automatico supportino obiettivi di gestione degli asset più ampi e una pianificazione basata sul rischio. Un'infrastruttura ben progettata non solo consentirà una distribuzione agevole dei modelli, ma permetterà anche alle previsioni di integrarsi perfettamente nei processi di manutenzione. Una volta che i sistemi sono pronti, il passo successivo è quello di valutare la propria preparazione attraverso un'accurata valutazione dei dati e dell'organizzazione.
Come valutare la propria preparazione
Iniziate con la verifica della vostra infrastruttura di dati. Consolidate e standardizzate le informazioni provenienti da fonti quali CMMS, sistemi SCADA e persino fogli di calcolo. Tenete presente che il 60% del successo dell'IA dipende dalla prontezza dei vostri dati. [12]. Se la qualità dei vostri dati non è all'altezza, prendete in considerazione l'implementazione di un quadro di governance dei dati. Strumenti come il catalogo dei dati e l'assegnazione di una chiara responsabilità per la gestione dei dati possono fornire una solida base.
Valutate quindi il livello di maturità della vostra organizzazione. Attualmente siete reattivi (risolvete i problemi dopo che si sono verificati), preventivi (seguite un programma fisso) o basati sulle condizioni (rispondete a soglie specifiche)? Stabilire questa linea di base vi aiuterà a fissare obiettivi realistici e a mostrare come il machine learning può migliorare la vostra strategia di manutenzione esistente. Decidete se investire nella formazione del vostro team attuale o se coinvolgere esperti esterni per colmare eventuali lacune.
Quando si avvia un progetto pilota, concentrarsi sugli asset che presentano guasti frequenti piuttosto che su quelli che sono semplicemente i più critici. Questo approccio fornisce più dati per la convalida dei modelli. Ad esempio, un grande produttore chimico ha sperimentato l'analisi predittiva sui suoi estrusori, ottenendo una riduzione di 80% dei tempi di fermo non pianificati e un risparmio di circa $300.000 per asset. [13]. L'identificazione di asset con alti costi di fermo macchina e chiari modelli di guasto nei dati può aiutare a dimostrare precocemente il ROI, aprendo la strada a un'implementazione più ampia.
Come implementare l'apprendimento automatico nella manutenzione
Fasi di implementazione
L'introduzione dell'apprendimento automatico nella manutenzione richiede un processo graduale, che inizia con la costruzione di una solida base per i dati. Ciò significa standardizzare i tag dei sensori, integrare i sistemi IT e OT e archiviare i dati delle serie temporali su una piattaforma affidabile, come un sistema ibrido o un lakehouse governato. [11]. Una struttura di dati ben organizzata pone le basi per il successo dei progetti pilota e per una scalabilità senza problemi.
Il passo successivo è l'esecuzione di un programma pilota con una categoria specifica di asset. Concentratevi sulle apparecchiature con chiari modelli di guasto e una storia documentata, piuttosto che sui beni più critici. Per esempio, l'U.S. Army Materiel Command ha testato una soluzione di "Predictive Asset Readiness" su sistemi d'arma selezionati. Utilizzando reti neurali ricorrenti, il sistema prevedeva la prontezza della missione e aiutava i pianificatori a mettere a punto i programmi di manutenzione e i livelli di inventario. [14]. Un progetto pilota come questo convalida il vostro approccio e crea fiducia prima di lanciarlo su scala più ampia.
Una volta che il pilota ha avuto successo, è possibile espandere la soluzione in tutto il portafoglio utilizzando modelli per classi di attività. Questi modelli fungono da guide riutilizzabili, facilitando l'integrazione di nuove apparecchiature senza dover partire da zero. [11]. Dopo l'implementazione, la supervisione continua del modello diventa una priorità per mantenere l'accuratezza e l'affidabilità.
Gestione dei modelli di apprendimento automatico nel tempo
I modelli di apprendimento automatico necessitano di una cura continua: non sono una soluzione "imposta e dimentica". Quando le risorse invecchiano e le condizioni cambiano, i modelli possono perdere precisione. Iniziate a monitorare la deriva dei dati, che comprende i cambiamenti nelle relazioni input-output, nelle letture dei sensori o nei modelli delle caratteristiche. [15]. Test statistici come il test di Kolmogorov-Smirnov o il test del Chi-quadro possono aiutare a individuare deviazioni significative. [15].
È fondamentale trovare il giusto equilibrio tra precisione e richiamo. Troppi falsi allarmi possono frustrare i tecnici e minare la fiducia. McKinsey sottolinea questa sfida:
"Un modello che genera numerosi allarmi può cogliere tutti i guasti (alto richiamo), ma è spesso errato e può non essere attendibile (bassa precisione)" [5].
Per risolvere questo problema, riunite data scientist, ingegneri dell'affidabilità e tecnici sul campo per mettere a punto i modelli. Chiudete il cerchio assicurandovi che i tecnici riferiscano sui risultati del lavoro e sugli esiti dei guasti. Questo feedback migliora l'accuratezza del modello nel tempo e aiuta ad affrontare le modalità di guasto rare che emergono con l'invecchiamento delle apparecchiature. [5]. Per gli scenari con dati storici limitati, le reti avversarie generative (GAN) possono creare dati di addestramento sintetici per colmare le lacune. [4]. Modelli affidabili, supportati da dati reali, possono quindi influenzare direttamente le decisioni operative.
Collegare le previsioni alle operazioni di manutenzione
Il passo finale consiste nell'incorporare queste previsioni nei flussi di lavoro quotidiani della manutenzione. Integrate i risultati del modello nei vostri sistemi CMMS o EAM per generare automaticamente gli ordini di lavoro. Includete i dati dei sensori, le azioni consigliate e i tempi di esecuzione per snellire i processi ed eliminare i passaggi manuali. [11][14].
Ad esempio, il Ufficio del programma congiunto F-35 ha sviluppato l'Artificial Intelligence Prognostic Steering Tool (AIPS) per gestire le riparazioni della sua flotta di aerei. Questo strumento utilizza l'apprendimento automatico per stabilire le priorità delle attività di manutenzione, prevedere i guasti e ottimizzare le prestazioni della catena di fornitura, riducendo i tempi di fermo e aumentando l'efficienza. [14]. La vostra implementazione dovrebbe seguire un approccio simile: assicuratevi che le previsioni portino ad azioni specifiche sul campo e che le lezioni apprese confluiscano in una base di conoscenze condivise.
Come Cloudera sottolinea:
"Se i tecnici non si fidano degli avvisi, li ignoreranno. Integrare le previsioni in flussi di lavoro familiari e misurare l'adozione, non solo la precisione"." [11].
Per incoraggiare l'adozione, impiegate dei "superutenti" che possano sostenere la soluzione e aiutare i loro colleghi ad adattarsi ai nuovi processi. [4]. Al di là delle operazioni quotidiane, le intuizioni dell'apprendimento automatico possono informare la pianificazione operativa e del capitale a lungo termine. Utilizzate i modelli di guasto previsti per guidare le decisioni di investimento pluriennali, ottimizzare le scorte e supportare le richieste di budget con dati solidi. Questo approccio trasforma l'apprendimento automatico da strumento tattico a risorsa strategica per la gestione dell'intero portafoglio.
Limitazioni e cosa aspettarsi
Limitazioni tecniche e di dati
L'apprendimento automatico mostra un potenziale nella manutenzione, ma prevedere i guasti non è semplice perché i guasti sono rari. Ciò significa che gli insiemi di dati sono spesso sbilanciati verso le operazioni normali, rendendo difficile l'addestramento di modelli in grado di prevedere in modo affidabile i guasti. [16][1]. Chi-Guhn Lee, direttore del Centro per l'ottimizzazione della manutenzione e l'ingegneria dell'affidabilità, evidenzia questo problema:
"Uno dei problemi unici delle applicazioni di manutenzione dell'apprendimento automatico è che la dimensione dei dati tende a essere inferiore rispetto alle applicazioni tipiche di apprendimento automatico, a causa di eventi di guasto relativamente rari"." [16].
La sfida è ancora più ardua scarsa qualità dei dati. I registri di manutenzione sono spesso registrati manualmente, il che può portare a registrazioni incomplete o imprecise di guasti precedenti. [4]. Anche quando i dati dei sensori sono disponibili, non è sempre semplice. Apparecchiature identiche, come le pompe, possono funzionare in modo diverso in base a fattori quali l'installazione o le condizioni ambientali, rendendo difficile applicare lo stesso modello a tutti gli asset. [1].
Un altro problema è la mancanza di dati dettagliati. Molti set di dati non includono informazioni critiche come il tipo di apparecchiatura, il produttore, la data di installazione o le condizioni operative. [16]. I sensori stessi possono presentare malfunzionamenti, fornire letture incoerenti o essere del tutto assenti nelle macchine più vecchie. La creazione di pipeline di dati affidabili dai dispositivi edge ai sistemi cloud rimane un problema tecnico. [3].
Ma le sfide non sono puramente tecniche: anche le pratiche organizzative giocano un ruolo significativo nel successo dell'apprendimento automatico nella manutenzione.
Sfide organizzative e di processo
I veri ostacoli spesso riguardano le persone e i processi, non la tecnologia. La resistenza al cambiamento è comune quando si introduce l'apprendimento automatico. I team di manutenzione potrebbero vedere le raccomandazioni guidate dagli algoritmi come una minaccia alle loro competenze o alla sicurezza del loro lavoro. Senza una comunicazione chiara da parte della leadership sui vantaggi, l'adozione può bloccarsi. [7]. Questi fattori umani possono compromettere i potenziali miglioramenti in termini di efficienza e risparmio.
Inoltre, molte aziende devono affrontare carenza di competenze. I talenti specializzati necessari, come i data scientist, gli ingegneri dell'apprendimento automatico e gli esperti di affidabilità, sono spesso assenti. [5][13].
Un altro problema è fatica per i falsi positivi. Se un modello genera troppi avvisi errati, i tecnici potrebbero iniziare a ignorare gli avvisi, anche quelli validi. McKinsey spiega che:
"Un modello che genera numerosi allarmi può cogliere tutti i guasti (alto richiamo), ma è spesso errato e può non essere attendibile (bassa precisione)" [5].
Anche le apparecchiature obsolete rappresentano un ostacolo. Le macchine più vecchie potrebbero necessitare di costosi interventi di retrofit con sensori per essere incluse in un sistema di manutenzione digitale. Anche se vengono generate delle previsioni, la loro integrazione con i sistemi CMMS o EAM esistenti può essere complicata. Se queste previsioni non si traducono in ordini di lavoro attuabili, il sistema rischia di diventare più un peso che un vantaggio.
Una volta affrontate le sfide tecniche e organizzative, il passo successivo è la comprensione delle tempistiche e dei potenziali ritorni.
ROI e tempi di realizzazione
La manutenzione predittiva ha il potenziale per ridurre i costi fino a 60% e migliorare l'efficacia delle apparecchiature oltre 90%, ma questi guadagni richiedono tempo. [1]. I primi modelli generano spesso falsi allarmi e richiedono un continuo perfezionamento per migliorare l'accuratezza. [5]. Possono passare mesi, o addirittura un anno, prima che i modelli funzionino in modo affidabile.
Il calcolo del ROI deve tenere conto anche di falsi positivi. Ad esempio, un tasso di falsi positivi pari a 10% potrebbe portare a una quantità di manutenzione non necessaria tale da annullare i risparmi derivanti da guasti correttamente previsti. [7]. Harold Brink, partner di McKinsey & Company, mette in guardia:
"Sebbene la manutenzione predittiva possa generare risparmi sostanziali nelle giuste circostanze, in troppi casi tali risparmi sono compensati dal costo degli inevitabili falsi positivi"." [7].
Quando il ROI si concretizza, deriva da diverse aree: evitare i guasti, ritardare le spese di capitale, ridurre i tempi di inattività non pianificati (spesso da 20% a 40%) e ridurre i costi totali di proprietà di circa 10%. [4].
Ad esempio, nel marzo 2016 l'Università del Queensland ha dotato 22 unità di refrigerazione di sensori IoT. Nel giro di sei mesi, hanno ottenuto un 135% ritorno sull'investimento, risparmiando circa $100.000 di costi di riparazione grazie alla prevenzione dei guasti [9]. Allo stesso modo, Voda AI ha aiutato un'azienda idrica della Florida a valutare oltre 1.200 tubature, riuscendo a prevedere 18 rotture evitabili e risparmiando più di $100.000 in costi di manutenzione reattiva [9].
Per massimizzare il ROI, è fondamentale dare priorità agli asset di alto valore - quelli con una solida copertura di sensori e una storia di guasti documentata. Questi tendono a fornire i migliori rendimenti. Per gli asset con dati limitati o modelli di guasto imprevedibili, metodi più semplici come il monitoraggio basato sulle condizioni possono offrire risultati migliori con una minore complessità. [7]. Iniziare con progetti pilota per dimostrare il valore prima di scalare in tutta l'organizzazione è spesso l'approccio migliore. Concentrarsi sugli asset critici e integrare gli insight predittivi nei flussi di lavoro quotidiani garantisce un successo a lungo termine. [14][3].
Manutenzione predittiva e altro: Come utilizzare l'apprendimento automatico senza essere uno scienziato dei dati
Conclusione: Far funzionare il Machine Learning per la vostra strategia di manutenzione
L'apprendimento automatico ha il potenziale per migliorare significativamente i risultati della manutenzione, riducendo i tempi di fermo non programmati di 20-40%, i costi totali di proprietà di 10% e le spese di manutenzione di 18-25%. [4][6]. Ma per ottenere questi risultati non basta installare sensori o implementare algoritmi. È necessario un approccio ponderato e graduale.
Iniziate a dare priorità agli asset che hanno il maggiore impatto sulle operazioni, sulla sicurezza o sulla produzione quando si guastano. Concentratevi sulle apparecchiature che hanno già una copertura sufficiente di sensori e una storia ben documentata di guasti. Prima di espandere gli sforzi, convalidare il ritorno sull'investimento (ROI) per gli asset di alto valore. Questo metodo non solo crea fiducia all'interno dell'organizzazione, ma fornisce anche prove concrete a sostegno di ulteriori investimenti. [3][14].
Assicuratevi poi che l'apprendimento automatico si integri perfettamente nei vostri processi operativi. Gli avvisi predittivi dovrebbero collegarsi direttamente ai sistemi di gestione del lavoro, consentendo risposte di manutenzione immediate e attuabili. [5]. La collaborazione tra data scientist e ingegneri della manutenzione è fondamentale per garantire che le raccomandazioni siano pratiche e allineate con le operazioni del mondo reale. [5][7]. Per favorire la fiducia e garantire un'adozione senza problemi, è necessario coinvolgere i tecnici fin dalle prime fasi, fornire una chiara definizione dei ruoli e offrire opportunità di formazione continua. [4][5].
Per favorire questa transizione, il Oxand SimeoLa piattaforma ™ può essere uno strumento prezioso. Con oltre 10.000 modelli di invecchiamento proprietari e 30.000 linee guida per la manutenzione sviluppate nel corso di due decenni, questa piattaforma basata su modelli aiuta le organizzazioni a pianificare CAPEX e OPEX pluriennali rispettando i vincoli di budget, energia e carbonio. Passando da una manutenzione reattiva a Pianificazione degli investimenti basata sul rischio, Oxand Simeo™ consente di risparmiare sui costi dei componenti mirati, di estendere la durata di vita degli asset e di supportare la conformità agli standard ISO 55001.
Con una strategia chiara, obiettivi realistici e un focus sugli asset ad alto impatto, l'apprendimento automatico può rivoluzionare il modo in cui mantenete e investite nella vostra infrastruttura.
Domande frequenti
Che tipo di dati sono necessari per utilizzare l'apprendimento automatico per la manutenzione?
Per implementare efficacemente l'apprendimento automatico nella manutenzione, occorre dati accurati e affidabili è fondamentale. Iniziate con i dati dei sensori di alta qualità che catturano le condizioni fisiche degli asset, come i livelli di vibrazione, la temperatura (misurata in °F) e la pressione. Questi dati devono essere il più possibile puliti, privi di rumori o errori eccessivi, perché le imprecisioni possono influire pesantemente sulle prestazioni dei modelli di apprendimento automatico.
Il set di dati deve essere ampio e completo, che incorporano i dati storici dei guasti, i registri di manutenzione, i dettagli operativi (come le capacità di carico o gli orari dei turni) e i fattori esterni come le condizioni ambientali. Anche la coerenza è importante. Utilizzate unità di misura standardizzate (come l'imperiale per le strutture con sede negli Stati Uniti), assicuratevi che i timestamp seguano un formato uniforme e includete metadati chiari per identificare le fonti dei dati.
Inoltre, la vostra organizzazione deve disporre dell'infrastruttura necessaria per raccogliere, memorizzare ed elaborare grandi volumi di dati in tempo reale o quasi.. Questa capacità è fondamentale affinché i modelli di apprendimento automatico forniscano previsioni accurate e tempestive. Stabilire solide pratiche di governance dei dati aiuterà a mantenere la qualità e la disponibilità dei dati a lungo termine.
Come possono le organizzazioni affrontare la resistenza all'adozione dell'apprendimento automatico nella manutenzione?
Per affrontare la resistenza in modo efficace, iniziare a garantire forte sostegno della leadership e presentare un chiaro business case. Evidenziate i risultati misurabili, ad esempio risparmio annuale in dollari o ore di riduzione dei tempi di inattività. Un piccolo progetto pilota su un singolo sistema può cambiare le carte in tavola, dimostrando risultati rapidi, come ad esempio un'ottima qualità di vita. 10% riduzione delle interruzioni non programmate, può contribuire in modo significativo a creare fiducia e sicurezza all'interno del team.
Altrettanto importante è il coinvolgimento precoce del personale addetto alla manutenzione. Incoraggiate la loro partecipazione a compiti come la raccolta dei dati, gli eventi di etichettatura e la formazione pratica sugli strumenti. Quando i dipendenti vedono che la loro esperienza viene valorizzata e capiscono che la tecnologia è progettata per migliorare il loro lavoro, non per sostituirlo, le preoccupazioni sulla sicurezza del lavoro spesso diminuiscono.
Infine, incorporate le strategie di gestione del cambiamento nel vostro lancio. Designate i campioni del team, fissate obiettivi chiari (ad esempio, $50.000 risparmi sulla manutenzione entro il 31 dicembre 2026) e celebrare le tappe fondamentali del percorso. Mantenete una comunicazione aperta e coerente, sottolineando come l'apprendimento automatico possa migliorare la sicurezza, aumentare l'affidabilità delle apparecchiature e ottimizzare l'efficienza. Questo approccio contribuisce ad alimentare una cultura del lavoro che abbraccia l'innovazione e il lavoro di squadra.
Quali fattori incidono sul ROI dell'utilizzo dell'apprendimento automatico per la manutenzione predittiva?
Il ritorno sull'investimento (ROI) di un programma di manutenzione predittiva basato sull'apprendimento automatico dipende da diversi fattori critici. Il primo e più importante, dati di alta qualità è indispensabile. Previsioni affidabili dipendono da dati accurati, puliti e completi, che contribuiscono a ridurre al minimo i falsi allarmi e a garantire l'efficacia del sistema. Altrettanto importante è la prestazioni degli algoritmi predittivi. Quanto più precisi sono questi modelli, tanto meglio possono prevenire guasti imprevisti, ridurre i costi dei pezzi di ricambio e le necessità di riparazioni d'emergenza.
Un altro elemento chiave è la perfetta integrazione con i sistemi di manutenzione esistenti. In assenza di ciò, le preziose intuizioni potrebbero non tradursi in azioni praticabili. Il competenza del team di manutenzione anche un ruolo significativo. Il personale qualificato è essenziale per interpretare i dati, programmare gli interventi e perfezionare i modelli predittivi per garantire il successo continuo. Infine, l'allineamento del programma con obiettivi aziendali più ampi, come la riduzione al minimo dei tempi di fermo, l'ottimizzazione della manodopera e l'aumento della disponibilità delle apparecchiature, ha un impatto diretto sui risultati finanziari.
Quando questi fattori vengono affrontati in modo efficace, i risparmi possono essere notevoli. Molte organizzazioni riportano cifre di ROI pari o superiori a 200%. Ad esempio, la riduzione dei tempi di inattività non pianificati, che possono costare migliaia di dollari al minuto, unita alla riduzione dei costi di manutenzione e al miglioramento della produttività, rende i vantaggi finanziari della manutenzione predittiva non solo misurabili, ma anche di grande impatto.
Post del blog correlati
- Manutenzione predittiva e reattiva: Guida all'analisi dei costi
- La manutenzione predittiva per la gestione degli asset (infrastrutture e immobili) è fondamentale - utilizzare il sito web https://theiam.org.
- Come la manutenzione predittiva (senza IOT e in tempo reale) apporta valore ai proprietari di infrastrutture e di beni edilizi
- Manutenzione predittiva e ROI