







Anomaly detection is changing how maintenance is done. Instead of waiting for equipment to fail or relying on fixed schedules, this approach uses machine learning to identify subtle changes in asset behavior. Even predictive maintenance without IoT can provide significant value by leveraging historical data and inspections. These insights can predict failures weeks in advance, saving businesses time, money, and resources.
Key Takeaways:
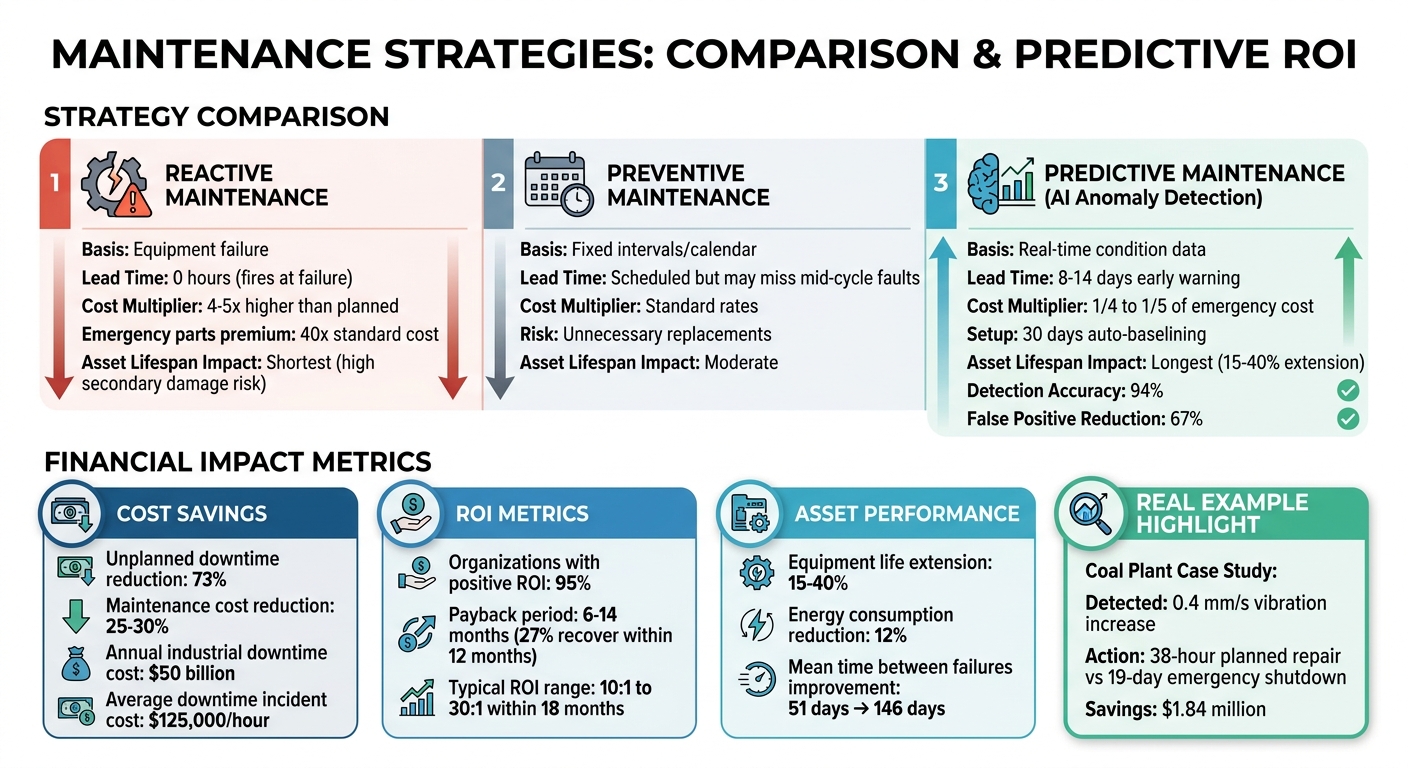
- Early Problem Detection: Identifies issues like vibration increases or temperature changes before they lead to breakdowns.
- Cost Savings: Planned repairs cost 4–5 times less than emergency fixes. For example, one coal plant saved $1.84M by avoiding a 19-day emergency shutdown.
- Efficiency Gains: Reduces unplanned downtime by up to 73% and maintenance costs by 25–30%.
- Asset Longevity: Extends equipment life by 15–40% through timely interventions.
- Energy and Resource Savings: Cuts waste, such as HVAC systems running during unoccupied hours, reducing costs and consumption.
Using tools like Oxand Simeo™, businesses can predict failures, optimize maintenance schedules, and make smarter investment decisions. The result? Fewer emergencies, lower costs, and better asset performance.
Predictive Maintenance ROI and Cost Savings Comparison
Time Series Anomaly Detection Techniques for Predictive Maintenance
sbb-itb-5be7949
How Anomaly Detection Works
Anomaly detection takes raw sensor data and turns it into actionable insights by understanding what "normal" operation looks like for each piece of equipment. It starts with baseline learning, where AI models – commonly autoencoders – analyze 30–90 days of historical data from equipment running under normal conditions [1][12]. During this phase, the system processes sensor readings (like vibration, temperature, and pressure) into statistical features such as RMS, kurtosis, and FFT bins [12]. This step ensures the data is in a format that machine learning models can work with effectively.
Once the baseline is established, the system begins real-time scoring. Every 1–60 seconds, live sensor data is compared to the learned "normal." If the reconstruction error surpasses a set threshold, the system flags it as an anomaly – even if the absolute values of the readings seem within acceptable ranges. For example, at a 310 MW hydroelectric station in 2026, continuous monitoring detected a rise in partial discharge from 200 pC to 840 pC over six weeks. Thermal imaging confirmed a hotspot 14°F higher than usual. This prompted a planned 9-day outage for stator rewedging, avoiding a replacement cost of $2.2 to $3.1 million and extending the generator’s life by 8–12 years [2]. This refined baseline allows for precise real-time anomaly detection.
What sets this technology apart is its reliance on unsupervised learning. Models like Isolation Forests and Autoencoders learn from normal operating data without needing labeled failure logs, which are often scarce [1][10]. This approach achieves a 94% detection accuracy for vibration data and provides an 8–14 day early warning window before catastrophic failures [1]. Even better, it reduces false positives by 67% compared to traditional threshold-based alarms [1].
Learning Normal Operating Conditions
Defining what constitutes "normal" for a machine is the cornerstone of effective anomaly detection. AI models auto-baseline by observing how equipment behaves under various conditions [1]. This is crucial because readings that are harmless in one context might indicate trouble in another. For instance, a high temperature during startup is expected, but the same reading during steady-state operation could signal a problem [11].
The system captures high-frequency signals – often at 25.6 kHz or more – to detect subtle energy shifts at specific mechanical frequencies, such as ball pass frequencies in bearings [13]. A single vibration sensor sampling at 10 kHz generates around 1.2 GB of data daily, making edge computing essential [12]. Edge devices handle signal filtering and feature extraction locally, cutting data volume by up to 99.99% before sending only the processed features and anomaly alerts to the cloud [12]. This ensures precise, cost-effective monitoring.
"AI-based anomaly detection is the process of identifying data points/patterns that deviate from an asset’s established baseline operating behavior." – Tredence Editorial Team [11]
However, "normal" isn’t a fixed state. Machines age, and operating conditions change, which means the system must engage in continuous learning to avoid concept drift – where an outdated baseline leads to missed failures or false alarms [11]. For instance, at a German automotive plant in March 2026, an AI system trained on 14 months of healthy data from a $3.2 million CNC machine detected a 0.3 mm vibration increase in a spindle bearing. The system predicted a 67% chance of failure within 72 hours. A scheduled downtime allowed technicians to replace the bearing for $180, avoiding a $650,000 unplanned repair and downtime cost [12].
With a solid baseline in place, the system can then use evolving patterns to predict potential failures.
Predicting Asset Failures
After learning what "normal" looks like, the system can estimate Remaining Useful Life (RUL) by tracking how patterns change over time. Advanced models like Long Short-Term Memory (LSTM) and Transformers are especially effective here, as they can spot gradual trends that static thresholds might miss [1][12]. These models analyze multiple signal features – such as vibration amplitude, frequency content, crest factor, and kurtosis – simultaneously to assess the severity of developing issues [13].
For example, at a 480 MW gas turbine in 2026, a heat rate model identified a 1.1% decline in compressor pressure ratio. This prompted an offline wash, restoring a 1.7% heat rate increase and boosting output by 8.4 MW. The plant saved $680,000 annually in fuel costs [2].
Real-time monitoring allows for defect detection weeks or even months before catastrophic failures occur [13]. Alerts are routed directly to Computerized Maintenance Management Systems (CMMS), minimizing "alert fatigue" and ensuring actionable insights are prioritized [13][12]. Since 82% of component failures are random and not age-related, relying on calendar-based maintenance schedules simply doesn’t match the precision of data-driven predictions [12]. In fact, AI-driven predictive maintenance can reduce unplanned downtime by about 50% and cut total maintenance costs by 25–30% [13][12]. This level of accuracy and efficiency makes a strong case for adopting predictive maintenance.
| Capability | Threshold Alarms | ML Anomaly Detection |
|---|---|---|
| Setup | 2–6 hours of expert tuning per asset | 30 days of auto-baselining [1] |
| Lead Time | Hours to none (fires at failure) | 8–14 days median early warning [1] |
| Adaptability | Static; requires manual re-tuning | Dynamic; continuously updating [1] |
| Failure Modes | Only pre-defined thresholds | Detects unknown/unseen deviations [1] |
Business Value of Anomaly Detection
The financial benefits of anomaly detection are clear: proactive maintenance costs 4–5 times less than emergency repairs [6]. Early detection of issues like bearing degradation can save on part costs, overtime pay, and expedited shipping fees (which can be 4 to 10 times higher than standard freight), as well as minimize production losses [6]. Unplanned downtime is a massive expense for industrial manufacturers, with annual costs reaching $50 billion and incidents averaging over $125,000 per hour [6].
The return on investment (ROI) is equally striking. 95% of organizations using predictive maintenance see positive returns, with 27% recovering their investment within 12 months [6]. AI-driven programs often deliver returns ranging from 10:1 to 30:1 within 18 months [3]. For instance, at a national logistics hub processing 84,000 packages daily, anomaly detection was implemented across 14 conveyor lines in April 2026. By identifying bearing vibration issues 8–12 days before failure, the facility reduced unplanned downtime by 70%, saving $1.4 million annually by avoiding downtime costs of $31,000 per hour and slashing emergency maintenance expenses from $148,000 to $22,400 [14].
"The total cost of the planned replacement was $240 in parts and 40 minutes of labor. Before OxMaint, that bearing would have failed mid-shift, taken the line down for four-plus hours, and cost us $130,000." – Ryan Castellano, Head of Engineering and Facilities, National Logistics Hub [14]
Reducing Downtime and Costs
Anomaly detection transforms maintenance from reactive fixes to scheduled interventions during off-peak hours. By identifying issues like vibration spikes, thermal drift, or current anomalies 3–14 days in advance, companies can avoid costly overtime and expedited part procurement, which can be 40 times more expensive than planned repairs [6][14].
For example, in April 2026, a 620 MW coal-fired plant detected a 0.4 mm/s vibration increase on a high-pressure turbine bearing just seven weeks after deploying AI monitoring. This allowed for a 38-hour planned repair instead of a 19-day emergency shutdown, saving the plant $1.84 million in lost generation and emergency labor [2]. The contrast between proactive and reactive approaches is stark: a planned industrial repair cost $6,500, while the same repair as an emergency soared to $261,000 [6].
Beyond direct costs, anomaly detection reduces unnecessary preventive maintenance by up to 32% [8]. A 15-building office portfolio eliminated calendar-based HVAC servicing in March 2026 using automated fault detection. Over 12 months, they identified 11 major faults before failure and cut preventive maintenance dispatches by nearly one-third, allowing technicians to focus on critical equipment [8]. This approach also avoids "secondary damage", where a failure in one component causes damage to surrounding parts, significantly increasing repair complexity and cost [6].
Extending Asset Lifespan
Early detection can extend equipment life by 15%–40% by addressing issues before they cause irreversible damage [7][3]. Using real-time condition data, predictive maintenance optimizes asset performance over the long term. For example, in March 2026, a 500,000 sq ft office complex used Facility Condition Index (FCI) scoring to assess equipment condition. They found that three HVAC units slated for replacement based on age still had 4 to 6 years of useful life, saving $310,000 in premature capital expenses [9].
"The first condition work order from OxMaint on our Building 3 chiller found exactly what the efficiency degradation curve had predicted. We fixed it for $4,100. The same failure in peak August would have cost us $34,000." – Vice President, Property Operations, 500,000 Sq Ft Commercial Office Campus [9]
Similarly, at an integrated steel manufacturing facility producing 2.4 million tons annually, IoT sensors predicted a bearing failure in an 8,500 HP blast furnace blower 16 days in advance. A planned $800 repair prevented a catastrophic failure that would have cost $187,600 in lost production and $45,000 in emergency premiums [4]. Over a year, the facility extended the mean time between failures from 51 days to 146 days and reduced emergency parts orders from 34 to just 7 [4].
| Maintenance Strategy | Basis for Action | Impact on Asset Lifespan | Cost Profile |
|---|---|---|---|
| Reactive | Equipment failure | Shortest; high risk of secondary damage | Emergency labor + expedited parts (40x premium) [6] |
| Preventive | Calendar/Fixed intervals | Moderate; risks over-servicing or missing mid-cycle faults | Standard rates but unnecessary replacements |
| Predictive (Anomaly Detection) | Real-time condition data | Longest; catches degradation before damage occurs | Planned repairs at 1/4 to 1/5 emergency cost [6][9] |
Improving Sustainability Metrics
Anomaly detection doesn’t just save money – it also reduces environmental impact. HVAC systems account for 40% to 60% of commercial building energy costs [15]. Continuous monitoring can uncover inefficiencies like refrigerant leaks, after-hours operation, and fault-driven overconsumption that traditional inspections often miss. A 15-building office portfolio discovered through IoT monitoring that three buildings were running HVAC units during unoccupied hours. Fixing this issue and addressing 11 fault conditions early cut HVAC energy costs by 25%, saving $94,000 annually with a 9-month ROI [8].
"We thought our HVAC spend was just the cost of running 15 buildings. OxMaint showed us that nearly a quarter of it was waste we could not see." – Portfolio Facilities Director, 15-building office group [8]
Condition-based maintenance also reduces the carbon footprint of maintenance activities. By cutting unnecessary technician dispatches and avoiding emergency parts shipping (often via air freight), companies lower resource use across their maintenance operations [8][4]. Research shows that 71% of HVAC failures leading to full system shutdowns exhibit measurable precursor conditions 7 to 21 days beforehand [15]. This gives teams enough time to source parts through standard shipping and schedule repairs during optimal windows, eliminating both energy waste and excess transportation emissions.
Using Oxand Simeo™ for Predictive Maintenance
Oxand Simeo™ takes predictive maintenance to the next level by simulating how assets age and perform over time. Instead of relying entirely on IoT sensors, the platform uses probabilistic aging models combined with existing asset data to predict failures and performance. With a library of over 10,000 proprietary aging and performance models and 30,000 maintenance laws – developed over two decades – it provides insights into asset degradation, energy consumption, and failure patterns throughout their lifecycle. This approach makes advanced failure prediction possible without the need for widespread IoT implementation.
Model-Driven Approach vs. IoT Dependency
While many predictive maintenance tools depend on constant real-time data from IoT sensors, Oxand Simeo™ stands apart by integrating historical data like repair logs, operating hours, and environmental conditions. By pairing this data with physics-based features, the platform uses probabilistic simulations and Digital Twins to uncover wear-and-tear patterns that traditional statistical tools often miss [17][18]. This method enables accurate failure forecasting and scenario planning, even for large portfolios of assets where sensor coverage is impractical.
Risk-Based CAPEX and OPEX Planning
Oxand Simeo™ extends its predictive capabilities to investment planning, offering a multi-criteria prioritization system. Users can run what-if scenarios to prioritize maintenance projects based on factors like risk, lifecycle cost, asset criticality, service levels, compliance, energy efficiency, and CO₂ impact. This allows organizations to optimize both predictive maintenance ROI and CAPEX over long-term timelines, shifting from reactive maintenance schedules to strategic, risk-focused planning. The platform even supports budget scenario testing for up to 50 years, helping companies allocate resources effectively while minimizing risks to safety, personnel, and assets [16].
ISO 55001-Compliant Reporting
Oxand Simeo™ simplifies compliance with its ability to produce audit-ready reports that meet ISO 55001 standards. These reports ensure that every maintenance decision is traceable, defensible, and supported by quantitative evidence. This feature is particularly valuable for infrastructure concession holders, public asset managers, and regulated industries that must demonstrate adherence to international asset management standards. By automating the documentation process, the platform saves time and ensures consistent compliance.
Building a Predictive Maintenance Business Case
Once you’ve covered the technical advantages of anomaly detection, the next step is to show how it impacts the bottom line. A convincing business case doesn’t start with tech specs – it starts with financial framing. Laura Zindel, Director of Assurance at Wiss, sums it up perfectly:
"Predictive maintenance is not a technology decision. It is a capital allocation decision with a quantifiable return. Build the financial model first" [6].
If your business case leans too heavily on sensor counts or software features, it’s likely to miss the mark. Instead, focus on what really matters: cash flow impact, payback periods, and risk reduction [22]. Use real numbers to show the dollars saved, downtime avoided, and the extended life of critical assets.
Establishing a Centralized Asset Inventory
Before diving into predictive models, you’ll need a structured and complete asset database. Start with a 90-day audit to review your CMMS (Computerized Maintenance Management System) history, interview operators about unlogged "micro-stoppages", and calculate the true cost of downtime [22]. This historical data is essential. Even spending a few weeks standardizing failure codes can boost detection accuracy by 40% within the first 90 days [2].
Your inventory should rank assets by Total Annual Failure Cost (frequency × average cost per event), not just by how often they break [7]. This approach helps identify the 10–20 key assets where a single failure costs over $10,000 – these assets typically account for 70–80% of total maintenance costs [21]. Once your asset data is cleaned and organized, you can effectively simulate potential failures and prioritize preventive actions.
Simulating Failure Scenarios
With clean asset data in hand, anomaly detection models can be used to forecast potential failures and prioritize maintenance tasks. Start by establishing a 30-day baseline to detect deviations that indicate wear, misalignment, or degradation [1][19]. When ranking work orders, consider the production impact of a prevented failure rather than just the severity of the anomaly [19]. Simulating failure scenarios helps teams plan maintenance during optimal windows, cutting down on emergency repairs and keeping assets running smoothly. Document every "caught failure" in your CMMS, including estimated avoided costs, to provide auditable evidence for leadership [2][22].
Quantifying ROI and Outcomes
The operational benefits of predictive maintenance are clear, but you’ll need hard numbers to prove its financial value. Calculate ROI using gross margin per hour rather than total revenue – this ensures your figures hold up under CFO scrutiny [21]. A thorough financial model should include six key areas: avoided unplanned downtime, lower emergency repair costs (which are 4–5× higher than planned repairs [19][21]), extended asset life, reduced inventory, improved quality, and better labor efficiency [7].
Use a break-even analysis to show that preventing just 2–3 major failures annually can often cover the entire program cost [22]. For example, between June and October 2025, a $12.7 billion healthcare manufacturer conducted a 4-month pilot with 234 wireless sensors. The results? The system prevented 30 hours of unplanned downtime and caught five major failures, including a motor drive shaft misalignment (saving $200,000) and a motor bearing failure (saving $154,000). With $405,500 in verified savings, the pilot achieved a 60× ROI [22].
To further strengthen your case, perform a sensitivity analysis across pessimistic, base, and optimistic scenarios. This ensures the investment shows a positive NPV, even if downtime reduction targets aren’t fully met [22]. Most facilities achieve full payback within 6–14 months [21], and the U.S. Department of Energy reports a 10:1 ROI for industrial predictive maintenance programs [20][21]. These insights provide a strong foundation for strategic maintenance planning, helping you maximize asset value while minimizing risks.
Applications and Success Stories
Infrastructure Use Cases: Ports, Highways, and Pipelines
Between 2021 and 2022, Shell scaled its predictive maintenance system to monitor over 10,000 assets – such as valves, pumps, and compressors – across six continents. This system processes an impressive 20 billion rows of data weekly from 3 million sensors. The results? A 20% reduction in unplanned downtime, a 45% drop in unplanned failures, and 20–25% savings in maintenance costs [24].
A global oil and gas leader upgraded its integrity management system for a staggering 150,000 miles of pipeline with the help of AI and drone-captured imagery. This modernization cut anomaly detection time from 1–3 days to under 5 minutes, leading to a 22% reduction in annual operational costs and an 18% boost in asset lifecycle performance [23].
At a 480 MW combined-cycle gas turbine plant, AI-based predictive maintenance identified compressor fouling just two months after deployment in April 2026. By performing an offline wash six weeks earlier than planned, the plant achieved a 2.1% heat rate improvement and saved an annualized $680,000 in fuel costs [2].
While these examples highlight large-scale industrial applications, anomaly detection also proves valuable in managing building portfolios, where operational efficiency directly affects financial outcomes.
Building Portfolios: Hospitals, Schools, and Offices
In April 2026, a 14-building office portfolio spanning 2 million square feet implemented AI fault detection across 186 HVAC units. Over 14 months, the portfolio recorded $1.44 million in annual savings, a 38% drop in maintenance costs, and a 71% decrease in emergency shutdowns [26]. The VP of Asset Management shared:
"We were spending $3.8 million a year on HVAC and could not tell our investors which buildings were driving the cost… By month six, we had cut emergency callouts by 71% and presented $1.44 million in documented savings to the board" [26].
Similarly, a 500-bed acute care hospital adopted AI-driven predictive maintenance in April 2026, moving away from paper-based schedules. By focusing on MRI, CT, and HVAC systems, the hospital achieved $1.8 million in first-year savings, a 67% reduction in unplanned downtime, and a 71% drop in HVAC-related clinical incidents. Predictive monitoring also improved MRI suite availability by 23% through early detection of cooling system and gradient coil issues [27].
An educational and research hospital expanded its intelligent monitoring system from 44 to 155 machines. This upgrade helped prevent 3 catastrophic failures, saving over $750,000, while also cutting the average cost per monitored machine by 75%. Early identification of issues in chilled water and steam systems played a key role in these outcomes [28].
These systems not only deliver financial and operational benefits but also contribute to energy efficiency and environmental improvements.
Sustainability-Driven Outcomes
In March 2026, a 15-building office portfolio installed IoT sensors over a 90-day period. By pinpointing HVAC inefficiencies – such as units running during unoccupied hours and detecting 11 pre-failure fault conditions like refrigerant leaks – the portfolio achieved a 25% reduction in HVAC energy costs, saving $94,000 annually. The project reached full ROI in just 9 months. The Portfolio Facilities Director remarked:
"OxMaint showed us that nearly a quarter of it was waste we simply could not see. Three buildings had units running full conditioning schedules every weekend with nobody in them. That one finding alone covered the platform cost in the first month" [29].
Vattenfall took a similar approach in 2026, implementing valve diagnostics across 2,000 heat transfer stations in the Netherlands. Using the Control Valve App, they identified over €200,000 per year in energy losses caused by inefficiencies like "hunting" and overshoot. By shifting to a usage-based replacement strategy, they extended asset lifetimes and reduced manual inspection needs [25].
Conclusion
Intelligent anomaly detection is revolutionizing predictive maintenance by shifting it from reactive fixes to proactive precision. By identifying potential issues 8–14 days ahead – and in some cases up to 42 days before a breakdown – this approach enables scheduled interventions during planned production pauses. The result? Lower costs and a significant reduction in unplanned downtime [1][30].
The financial benefits are undeniable. Companies using anomaly detection report an average 73% decrease in unplanned downtime [1][2]. Emergency repairs, which can cost 4.8 to 5 times more than planned maintenance, are largely avoided [1][7]. Most industrial programs recover their investment within 6–14 months, with ROI figures ranging from 10x to 30x within 12–18 months [5][7]. The advantages don’t stop there – predictive strategies can extend equipment life by 20–40% and cut energy consumption by an average of 12% [5]. These measurable outcomes make a compelling case for adopting advanced maintenance solutions.
Technological advancements amplify these benefits. For instance, Oxand Simeo™ uses a model-driven approach that eliminates the need for extensive IoT sensor networks. With over 10,000 proprietary aging models and 30,000 maintenance laws developed over two decades, the platform simulates asset degradation and failure. This allows organizations to create risk-based CAPEX and OPEX plans, prioritizing interventions based on factors like failure likelihood, operational impact, and budget constraints. Additionally, the platform generates ISO 55001-compliant, audit-ready reports, further simplifying asset management.
Predictive maintenance isn’t just about adopting new technology – it’s a strategic decision with clear financial returns. As Laura Zindel, Director at Wiss, aptly put it:
"Predictive maintenance is not a technology decision. It is a capital allocation decision with a quantifiable return. Build the financial model first" [6].
To achieve sustained success, organizations should focus on documenting baseline failure costs, targeting critical assets early, and recording every prevented failure in their CMMS. This approach integrates technical expertise with financial planning, reinforcing the importance of risk-based asset investment strategies for long-term operational excellence.
FAQs
What data do I need to start anomaly detection?
To kick off anomaly detection, start by gathering data that represents how your assets perform during operations. This typically includes sensor readings such as vibration levels, temperature, and pressure. Additionally, historical records like maintenance logs and work orders are crucial.
The quality of your data matters – a lot. If your data is inconsistent or incomplete, it can hurt the accuracy of your detection efforts. Make sure your dataset includes both normal operating conditions and instances of known failures. This combination is vital for training AI models that can effectively spot early signs of potential issues.
How do I pick the first assets to monitor?
To kick off predictive maintenance, start by targeting assets where failure would hit the hardest – whether in terms of costly repairs, extended downtime, or safety concerns. Zero in on critical equipment that plays a key role in operations. Look for warning signs like unusual vibrations, energy usage spikes, or odd patterns in work order notes. Using AI-powered tools can help detect these subtle signs of wear and tear, ensuring your maintenance efforts focus on the assets that matter most.
How do I prove ROI to a CFO?
When presenting ROI to a CFO, it’s all about focusing on clear, measurable financial metrics. Highlight areas like cost savings, reduced downtime, and payback periods. Make your case stronger by using real-world data to establish baseline failure costs, calculate intervention savings, and project ROI.
For instance, emphasize how implementing changes can lead to tangible benefits such as:
- Reduced unplanned downtime by 25-45%
- Lower maintenance costs by 25-40%
- Increased equipment lifespan
By framing your argument with specific, data-driven projections, you can clearly demonstrate the financial impact and value of your proposal. Keep the focus on numbers that resonate with the CFO’s priorities.
Related Blog Posts
- Predictive Maintenance for Asset Management (Infrastructure and Real Estate) is critical – use the web site the web site:https://theiam.org
- How predictive maintenance (without IOT and real time) brings value to infrastructure and building asset owners
- Predictive Maintenance & ROI
- Machine Learning in Maintenance: What You Can Realistically Expect